《Sider:Singleimage neural optimization for facial geometric detail recovery》
paper: 2108.05465.pdf (arxiv.org)
code: none
1、目标
单图人脸几何细节重建
结合3DMM和SDF的隐式几何表达用神经网络做优化
2、贡献
提出了SIDER,一种无监督从单图重建人脸几何细节的方法;
提出了一种新颖的从粗到精的优化方案,该方案利用经典的3DMM模型表示作为先验来防止 SDF 的退化解决方案,并使用无监督的光度损失进行优化;
3、方法
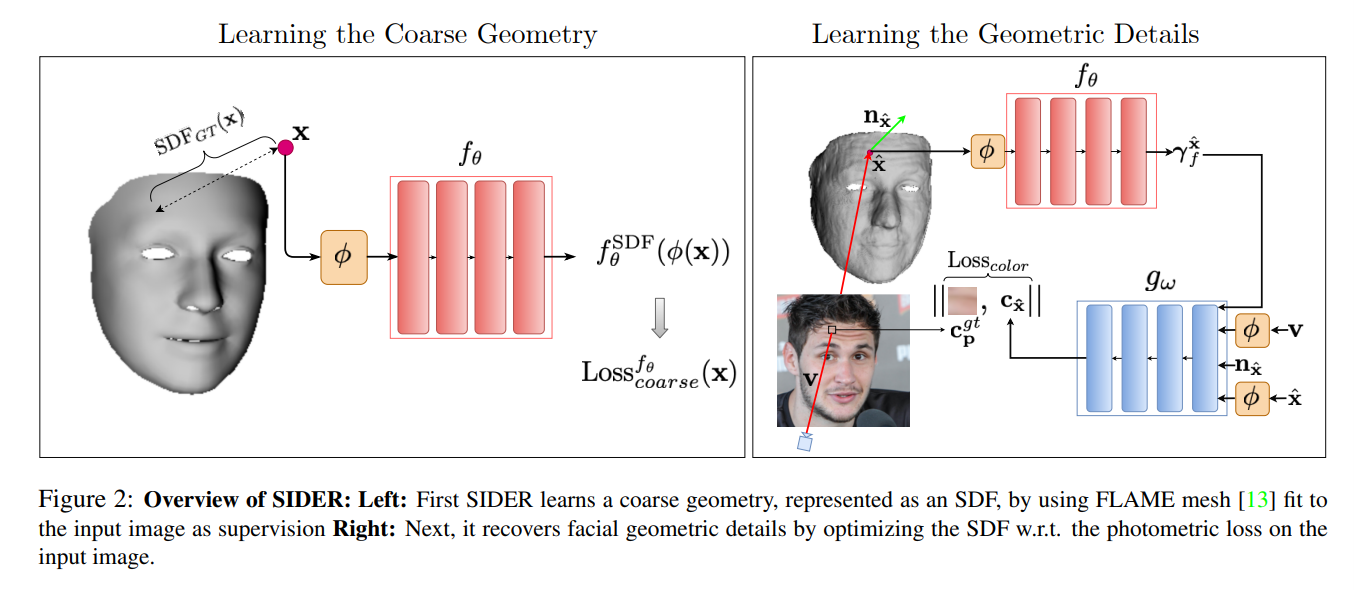
给定单个图像,SIDER 旨在从中提取面部几何细节,例如皱纹和皮肤褶皱。
SIDER 使用两阶段神经优化方法来提取这些细节。 在第一阶段,我们先利用 FLAME 可变形模型 ,以学习面部的粗略几何形状,其表示为 SDF。
接下来,我们根据所提供图像 I 的光度损失来优化此 SDF,以学习面部几何细节。 下面我们详细阐述SIDER的运作和训练过程。
3.1 架构

几何网络预测两种数据:
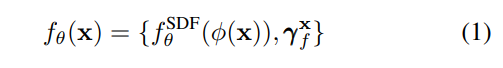
前者为对应一个点x上经过位置编码所预测的SDF值;后者为在x处预测的特征向量用于输入渲染网络。
渲染网络输入输出如下:
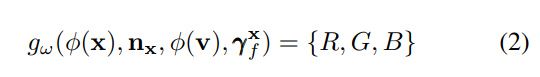
输入经过编码后的x,x处的法线,经过编码后的视角,在几何网络种预测的x处的特征向量。
3.2 学习粗糙几何结构
基于FLAME(与全身的SMPL类似)
基于FLAME的三维人脸重建技术总结 - 知乎 (zhihu.com)
基于LBS(linear blend skinning)并结合blendshape(并非arkits规则)作为表示
给定一张图像I,FLAME使用standard landmark来拟合:
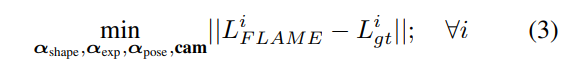
前一个L是FLAME模型的第i个landmark的位置,后一个使用3DDFA预测得到的landmark作为GT值,优化的参数为FLAME模型的shape,exp,pose参数以及相机参数。训练一个MLP来进行拟合。
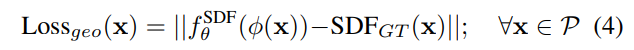
其中P是FLAME模型附近空间中随机选取的一组点;x是此空间中一个点;φ 是位置编码;SDFGT (·) 是针对粗糙网格的SDF的GT值;由于 FLAME 网格是一个开放且单一的表面层,因此无法直接在其上定义 SDF(不存在距离为负的区域,因为没有“内部”)。 因此,为了定义SDF,将网格视为一个有“厚度”的体积物体。 这使我们能够将真实 SDF 定义如下:
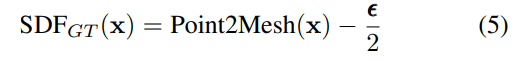
其中 Point2Mesh 是点到网格的距离函数,是一个表示网格厚度的小数字。
此外,几何网络使用 eikonal 损失进行正则化:
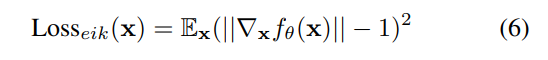
3.3 恢复面部几何细节
使用输入的原始图像I来fine-tune几何网络以恢复几何细节。
为渲染SDF,使用sphere-tracing结合渲染网络。光线从相机中心o射入场景,并使用球体追踪和隐式微分来估计这些光线与面部网格的交点,更通俗地说,使用渲染网络预测相交点的RGB值。
具体使用Multiview Neural Surface Reconstruction by Disentangling Geometry and Appearance这篇文章中的方法。
更通俗地说,考虑一条射线,r = o + vt,其观察方向为 v,表面交点为 xˆ。xˆ 处的 RGB 颜色计算如下:
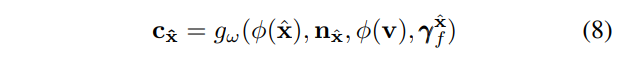
就是上面的公式
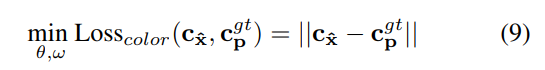
总体的几何细节生成loss
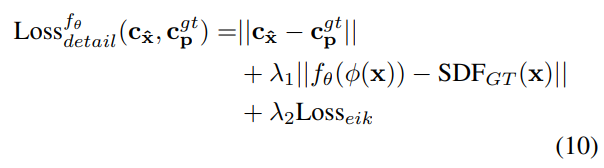
4、实验
4.1 实施细节
数据集
FFHQ ALFW2000 NoW
resize到256
几何网络
8层全连接 一个残差连接(从input到第四层)与Multiview Neural Surface Reconstruction by Disentangling Geometry and Appearance文中结构相似
渲染网络
四层全连接,其输入被非线性映射以学习高频。两个MLP的每一层都包括512个隐藏单元。
首先对几何网络进行1000个epoch的训练,以学习粗略几何形状。然后,通过优化对其进行微调,并联合训练渲染网络约200-300个epoch。使用Adam优化器,学习率为10-4。