《REALY:Rethinking the Evaluation of 3D Face Reconstruction》
paper: REALY (realy3dface.com)
code: czh-98/REALY: REALY: Rethinking the Evaluation of 3D Face Reconstruction (ECCV 2022) (github.com)
ref link:https://blog.csdn.net/jiafeier_555/article/details/125428388
1. 贡献
提出一个3D face reconstruction的benchmark REALY(Region-aware benchmark based on the LYHM Benchmark)
REALY,HIFI3D++(3DMM),本文的新evaluation pipeline以开源。
2. 动机
人脸重建任务中,不同的数据集,会制约重建方法、评估方法、3DMM基底的发展。
现有的开源 3D 人脸数据集存在一些不可忽视的缺陷。 例如,面部扫描具有不同的比例和随机姿势,并且提供的关键点不够准确或辨别力不够,这使得将输入形状与预测面部对齐以进行评估变得极其困难。 此外,由于原始面部扫描中缺乏真实标注,标准评估管道依赖于最近邻对应来衡量扫描与估计面部形状之间的相似性,这完全忽略了实体特征并丢弃了人体的几何形状面孔。
3. 简介
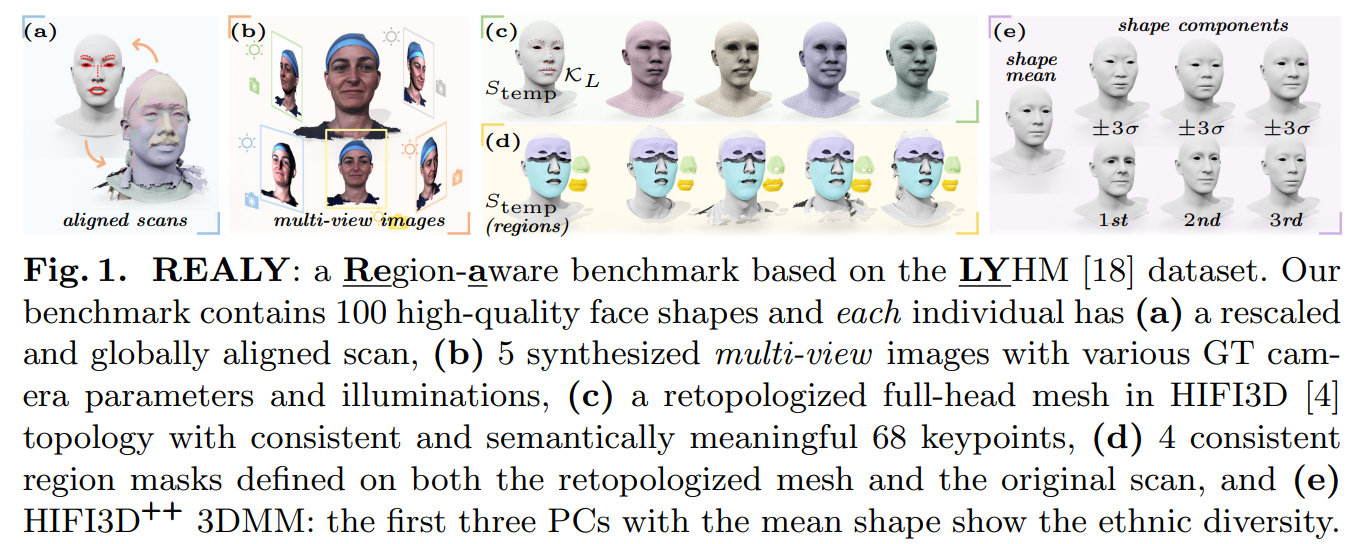
为了填补这一空白,提出了一个名为 REALY 的新基准,用于评估 3D 人脸重建方法。 REALY 包含来自 LYHM 数据集的 100 个人的 3D 人脸扫描,其中人脸扫描被一致地重新缩放、全局对齐,并展开成拓扑结构一致的mesh。 更重要的是,由于本文已经预定义了重新拓扑网格模板的面部关键点keypoints和掩码masks,因此可以将keypoints和masks转移到原始面部扫描结构中。 在这种情况下,本文即获得了原始原始面部扫描的高质量面部关键点和蒙版,这使我们能够对估计的 3D 面部形状执行更准确的对齐和细粒度的区域评估。
我们的基准包含来自不同种族、年龄和性别群体的个体。 利用为 REALY 构建的重新拓扑步骤(已开源),我们通过对齐和重新拓扑多个 3D 人脸数据集,进一步提供了一个名为 HIFI3D++ 的 3DMM 基底。 我们进行了广泛的实验来评估最先进的 3D 人脸重建方法和 3DMM 基底。
4. 预备知识
符号定义

三个特殊的face shape,以及在不同face shape上的keypoints和regions



NMSE用于度量两个surfaces之间的距离

ICP可用于通过迭代求解刚性变换和最近邻映射来对齐两个shape,以最小化NMSE
3DMM补充
一些开源的3DMM数据:
一些标准的evaluation pipeline
一些数据集还提供ground truth scan数据

motivation
传统standard evaluation pipeline的缺陷
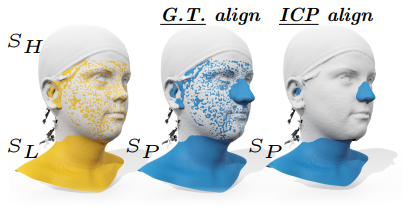
如上图,使用standard evalution pipeline,高分辨的shape和gt shape的差异反而要比低分辨率的shape的高。所以考虑regions的对齐比较合理。
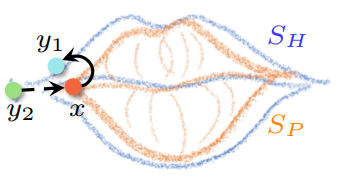
如上图,x对应的最近邻点是y1,而根据语义x应该与语义y2计算NMSE。
结论
需要考虑基于region和双向对齐
=》提出真实语义区域的region masks的shape进行度量=》现存数据集都未设定这样的规则=》本文方法
5. REALY:A New 3D Face Benchmark
100个个体
每个个体包含高分辨率shape(来自LYHN的aligned 3D scan)和低分辨率shape(使用HIFI3D基底拓扑进行重新拓扑化)
所有shape始终等比例缩放对齐,
同时每个shape都有68个keypoints和4个region masks
对于每个个体,使用精心设计的照明条件和gt相机参数渲染出5张高质量的多视图图像(包括1张正面图像)

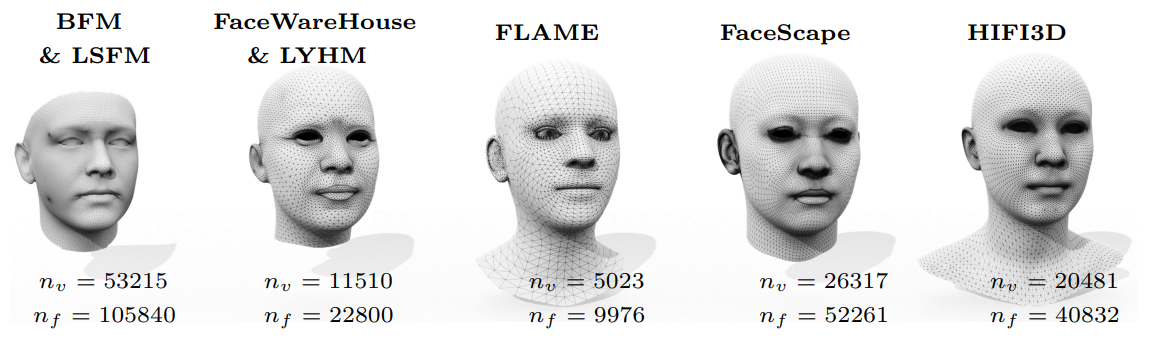
选择HIFI3D基底作为目标拓扑的原因
LYHM 在眼睛和嘴巴的边界处有过密的采样;
LSFM 没有边缘循环来定义眼睛和嘴巴的轮廓;
FLAME的三角剖分不自然,无法模拟一些逼真的肌肉动作,比如抬眉毛。 作为比较,HIFI3D 具有更好的三角剖分和平衡采样,可以做出逼真和细腻的表达。
此外,HIFI3D还有眼球、嘴巴内部结构、肩部区域等,这些都将有利于下游应用。
数据集构建步骤
第一,从 LYHM 收集 1235 个scans数据,并在 HIFI3D 拓扑中准备模板形状 Stemp,其中预定义了 68 个关键点 Ktemp 和 4 个区域掩码 Rtemp(包括鼻子、嘴巴、前额和脸颊区域)。
第二,将输入扫描重新缩放并严格对齐到模板形状 Stemp,从而生成我们的真实高分辨率网格 SH(即对齐扫描)。
第三,定义一个评估区域(有相关论文),该区域是一个以鼻尖为中心的圆盘。
第四,将 Stemp“包装”(即执行非刚性配准)到每个 SH 以获得重新拓扑化的 SL,使得 SL 具有与 Stemp 相同的拓扑但反映 SH 的形状。(高分配准低分) 请注意,我们有关键点 KL = Ktemp 和区域 RL = Rtemp,因为 SL 和 Stemp 共享相同的 HIFI3D 拓扑
第五,将每个人的 KL 和 RL 从 SL 转移到 SH。(低分的region和mask转移到高分) 我们还设置了一个渲染管道,用于为带纹理的高分辨率网格 SH 合成多视图图像。 这种受控环境使REALY能够专注于反映不同方法的重建能力。
第六,过滤掉wrapping error(这里不理解)大于 0.2mm 的样本,并请具有 3 年建模经验的专家艺术家从所有处理过的扫描中选择 100 个具有最高模型质量的个体,跨越不同的性别、种族和年龄,以获得我们的真正的基准(最终人工筛选高质量模型)。


挑战与解决方案
挑战一:原始扫描具有不同的比例和姿势,具有不准确的稀疏keypoints,这使得它们难以一致地对齐。
为了解决这个问题,我们迭代以下步骤直到收敛:
第一,渲染一张高分shape的前脸、带纹理的图像(使用initial/estimated transformation)来对齐SH到Stemp(注意正面姿势需要alignment transformation,因为对于给定的scan数据,正面姿势是未知的需要进行统一对齐);
第二,使用sota的landmark detector来检测这张渲染图像的2D 面部keypoints;
第三,使用渲染相机视角将 2D 关键点投影到 3D;
第四,使用 SH 上的投影 3D 关键点与 Stemp 上已知的 3D 关键点之间的对应关系,更新从 SH 到 Stemp 的对齐变换。
挑战二:得到重新拓扑的 SL 之后,如何准确地将region masks从 SL(继承自 Stemp)转移到SH
一种天真的解决方案是使用从 SL 到 SH 的最近邻映射来传输区域掩码。 然而,由于 SH 的分辨率可以比 SL 的分辨率大 50 倍,这种天真的解决方案将引入断开连接和嘈杂的区域掩码。 为避免此类缺陷,我们从两个方向使用顶点到点映射来查找 SH 上的候选区域。
由于在从 SH 到 SL 的映射过程中可以建立更多的对应关系,因此可以获得更高质量、更平滑的区域掩码。 最后,我们过滤掉噪声区域(例如,鼻孔、眼球)并返回最大的连接区域。
HIFI3D++
通过以上过程,我们可以通过对更多的3D人脸模型进行重新拓扑来进一步构建新的3DMM基底。
具体来说,基于来自 HIFI3D 的 200 个个体,我们另外处理和重新拓扑来自 FaceScape 数据集的 846 个个体的 3D 人脸模型到 HIFI3D 拓扑中。 连同上述来自 LYHM 的 1235 个个体的处理模型,我们收集并选择了 1957 个最具代表性的mesh数据。
然后,我们应用 PCA 获得我们的新基底,包含 526 个 PC(具有 99.9% 的累积解释方差),我们将其命名为 HIFI3D++。
下图显示了 HIFI3D++ 与其他 3DMM 的比较。 请注意,以前的 3DMM 或多或少存在种族偏见。 例如,BFM 主要由欧洲人构建,FLAME 由美国和欧洲的扫描构建,而 HIFI3D 和 FS 由亚洲人的扫描构建。
LSFM 和 FLAME 分别包含 50 : 1 和 12 : 1 的白种人和亚洲人。 相比之下,HIFI3D++ 由跨越更平衡的种族群体的高质量模型构建,确保白种人和亚洲人(加上来自其他种族的一些受试者)之间的比例为 1:1。

6 创新的Evaluation pipeline
本文提出的pipeline就是采用rICP+bICP取代standard pipeline的直接gICP
在REALY的基础上,我们提出一个新的评价流程避免先前评价流程的问题,具体而言,我们的评价流程包含如下两个步骤:
(该两步分别对应上文的motivation)
第一,局部区域的对齐 region-aware ICP(对齐region)
考虑到不同区域的重建质量会影响全局的对齐结果,由于我们的benchmark得到了不同脸部区域的mask,因此我们可以借助这个信息将predicted mesh对齐到ground-truth scan的特定区域,在error计算时只计算ground-truth scan上的特定区域与predicted mesh之间的误差,而不考虑脸部其他区域对于对齐结果以及误差计算的影响。

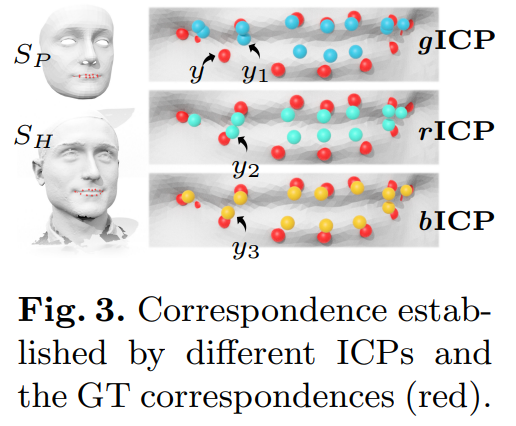
第二,对应关系的建立 non-rigid and bidirectional ICP(构建点对)
在局部对齐的基础上,我们需要建立ground-truth scan某一区域上的每一个点与predicted mesh之间的对应点并计算两者的误差。考虑到先前基于最近点的方式存在的问题,我们提出一个新的对应关系的建立方法,提高了关键点语义信息的一致性。

具体而言,我们首先通过最近点建立初步的对应关系(region-aware ICP);随后借助non-rigid ICP将ground-truth scan某一区域变形到predicted mesh上,由于变形后的区域与predicted mesh已经贴合,因为在变形过程中考虑了具备语义信息的关键点损失,所以这时的对应关系相比于原始的最近点的对应关系具有更好的语义关系的一致性(如,图3中脸部关键点的一致性),从而我们对初始的对应关系进行更新;最后,由于变形前后的拓扑形状的一致性,我们能够借助更新后的对应关系计算原始的ground-truth scan区域与局部对齐的mesh之间的最终误差。
下图为三种ICP后gt和predicted的关联度
7. 实验
消融实验:bICP VS gICP

从图4来看,全局的对齐策略由于局部区域的改变容易导致全局误差的变化,而我们的对齐策略则只聚焦于特定区域,其中对角线的error map表明误差较大的区域,而非对角线的error map的误差较小,对应没有发生变化的区域。
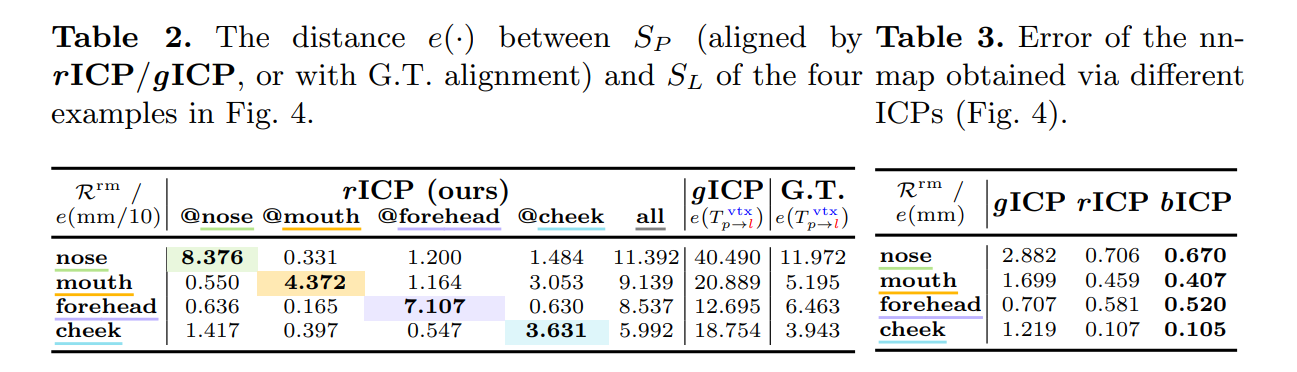
从表2来看,我们的对齐结果通过ground-truth的对应点计算得到的误差与真实的误差更为接近,而全局的对齐策略则导致误差与真实误差不匹配。
从表3来看,我们的对应点计算策略带来的误差要显著小于全局对齐后最近点获得的对应点。实验结果表明,我们的评价流程不仅能够聚焦到脸部区域有差异的部分(图4和表2的对角线),并且我们的对应关系建立更加准确(表3)。
不同方法在REALY benchmark上的表现
具体可见REALY官网列表
我们对比了先前的评价流程与我们提出的评价流程在REALY benchmark上的表现。对于先前的评价方法,我们从两个方向(即ground-truth scan的每个点与predicted mesh建立对应关系,以及predicted mesh每个点与ground-truth scan建立对应关系)作为对比,定量与定性的比较如表4和图5所示。
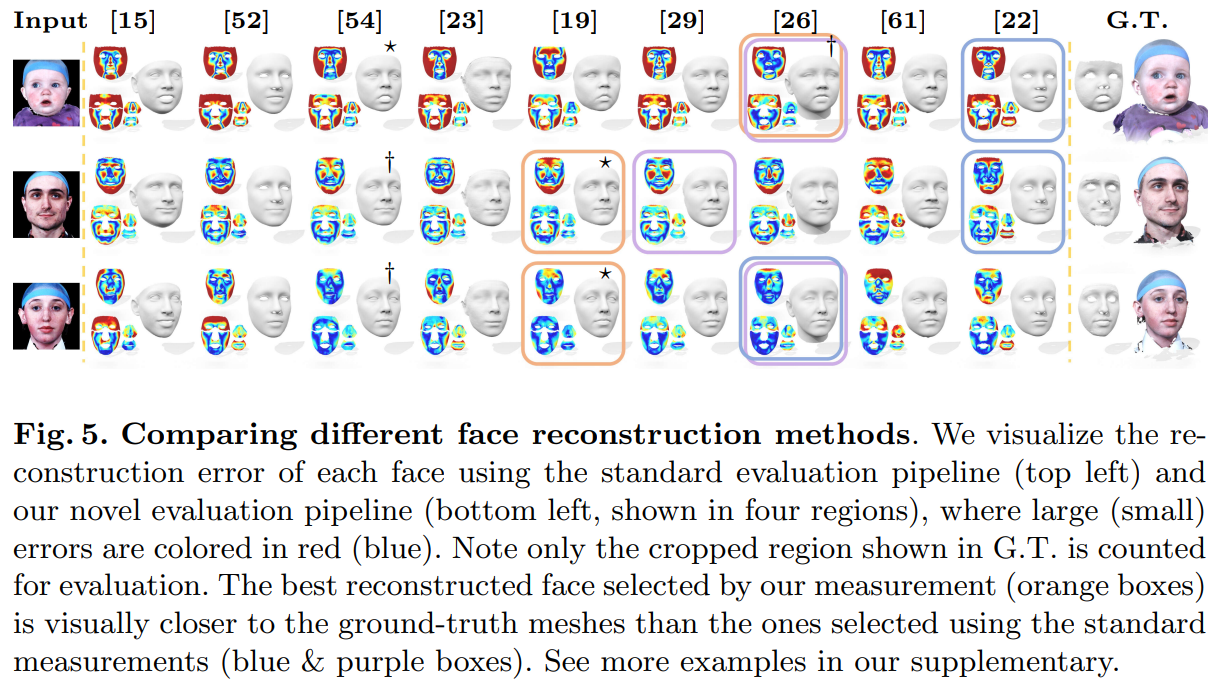
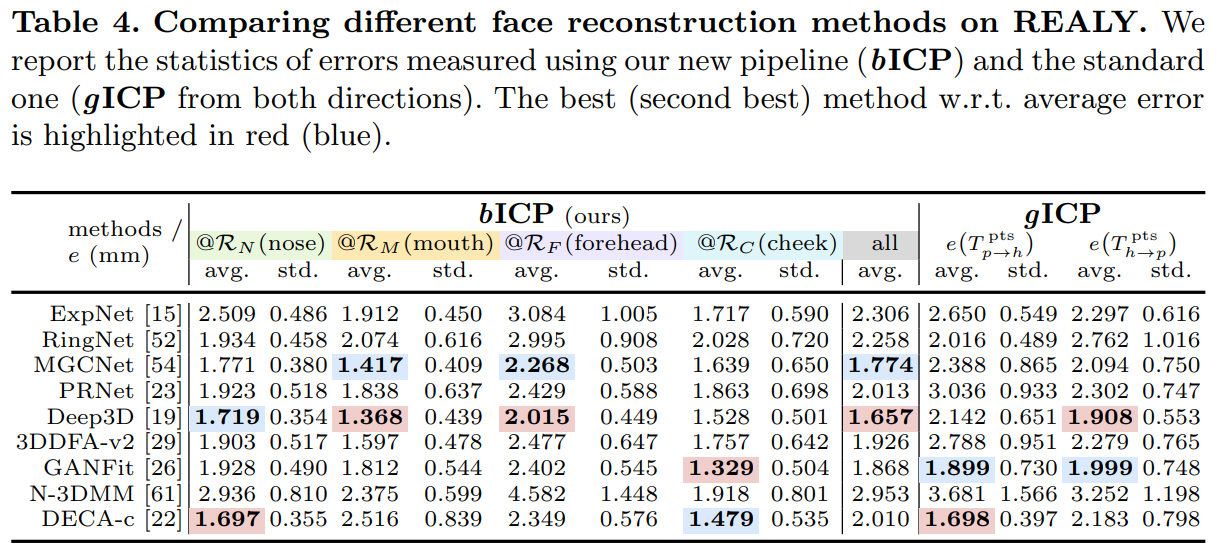
我们通过user study投票选出各组最好(*)/次好(†)的人脸,通过比较不同评价流程选出的最好的人脸(橙、蓝、紫框)可以发现,我们的评价流程(橙框)选出的最好的人脸与user study的投票结果匹配程度更高。并且,我们的评价流程给出了细粒度的评测结果,即:对不同的人脸区域都能进行定量的评价和比较。
不同3DMM在REALY上的表现
借助REALY benchmark,本文采用RGB(-D) Fitting的方式对不同3DMM的表达能力进行了评价,定量与定性的比较如表5和图8所示

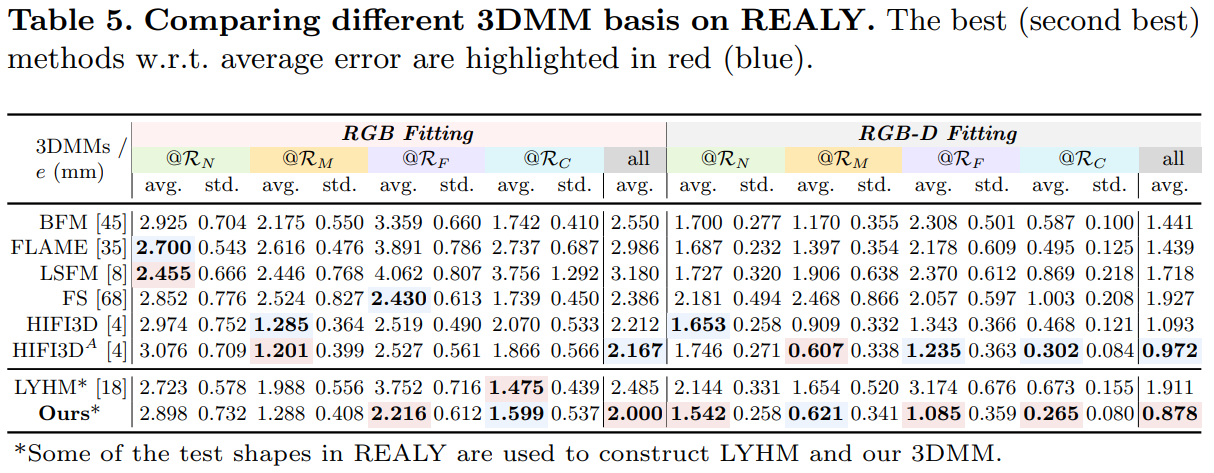
定量和定性的结果表明,我们的3DMM在REALY上取得了更优的重建效果,并且,通过不同方法的比较表明,RGB-D Fitting的结果要显著优于目前最好的重建算法,3D人脸重建任务仍有很大的提升空间。
为了进一步证明HIFI3D++的表达能力,我们只用顶点损失,根据最小二乘的方式拟合一组mesh,对HIFI3D/HIFI3D(A)/HIFI3D++进行比较,如图9所示。

8. 总结
本文是我们对3D人脸重建评价的重新思考和探索。针对先前的评价指标无法准确衡量重建mesh与ground-truth相似性的问题,我们构建了一个新的数据集——REALY,包含更加丰富以及高质量的脸部区域信息,并借助新的评价流程对先前的数十个重建算法、3DMM进行了评价。