《High-Fidelity 3D Digital Human Head Creation from RGB-D Selfies》
paper: https://arxiv.org/abs/2010.05562
ref link:https://blog.csdn.net/jiafeier_555/article/details/125428388
1. 实现效果
将用户的RGB-D自拍作为输入,自动生成高保真、可装配的头部模型,以及高分辨率的纹理图和法线图。
2. 全部算法总览
2.1 数据集
包含各100名男女性的3D人脸,20481个顶点和40832个面片,每个模型对应2K分辨率的纹理图和法线图。
2.2 目标
用RGB-D自拍数据捕捉高保真用户的面部几何形状和反射率,该数据进一步用于创建和渲染全头、逼真的数字人类。对于几何建模,我们使用3DMM参数来表示一个面,因为它对低级别的输入数据更鲁棒,并且与基于变形的表示形式相比,网格质量更可控。对于纹理建模,我们合成了2K分辨率的反照率图和法线图,而不考虑输入的RGB-D分辨率。
2.3 用户输入数据
需要通过带深度相机的手机设备采集RGB-D数据,腾讯其有个采集软件,拍摄界面将引导用户连续向左、向右、向上和向后中间旋转头部。整个采集过程不到10秒,总共采集了200-300帧RGB-D图像,分辨率为640×480。用于计算的面部区域被裁剪(并调整大小)为300×300。相机的固有参数直接从设备读取。
2.4 处理管线
我们首先使用自动帧选择算法来选择覆盖用户所有侧面的几个高质量帧(第4节)。然后,使用所选帧中检测到的面部标志计算初始3DMM模型拟合(第5.1节)。从初始拟合开始,应用基于可差分渲染器的多视图RGB-D约束优化(第5.2节)来求解3DMM参数以及照明参数和姿势。根据估计的参数,合成高分辨率反照率法向图(第6节)。最后,可以创建和渲染高质量、逼真的全头像(第7节)。
3. 具体算法
3.1 帧选择
通常从用户获取200-300帧。为了提高效率和健壮性,我们开发了一个健壮的帧选择程序,以选择几个高质量的帧进行进一步处理,该程序同时考虑了视图覆盖和数据质量。如图2所示,该过程包括如下所述的两个阶段。
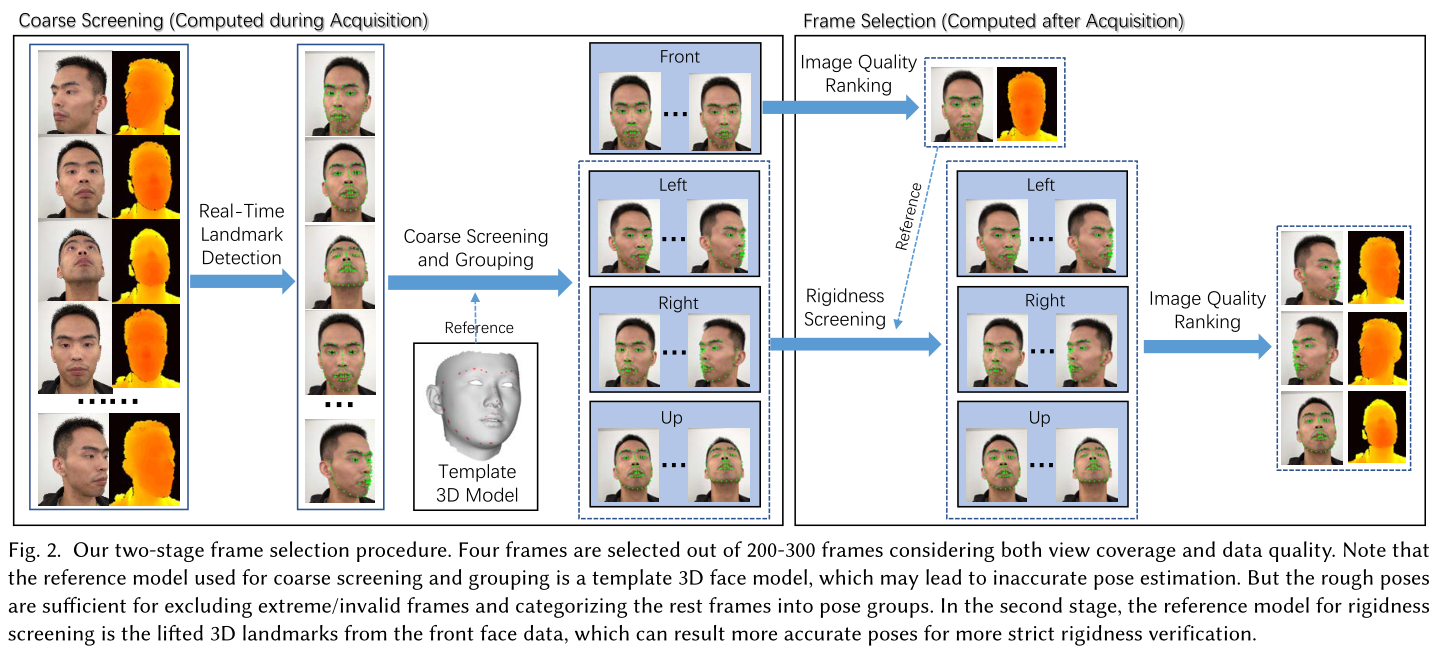
3.1.1 粗筛和预处理
首先用了个face landmark的检测(在300W-LP数据集上训练的MobileNet)来检测2D landmark;
然后,可以使用PnP算法利用模板3D面部模型上的2D地标和3D关键点之间的对应关系有效地计算每个帧的粗略头部姿势;
使用2D地标和粗略的头部姿势可以很容易地识别和筛选出具有极端无效姿势或闭眼张开嘴表情的帧。我们根据姿势将其余帧分类为组:前、左、右和上;
3.1.2 帧选择
对于每组,我们进一步根据两个标准选择一个帧:图像质量和刚性。为了测量帧的图像质量,我们计算拉普拉斯高斯(LoG)滤波器响应,并将方差用作运动模糊分数(分数越大的图像越清晰)。首先基于前面组中的运动模糊分数来选择前面帧。然后,我们利用深度数据计算其他组中的每个帧与正面之间的刚度。具体而言,使用深度数据将每个帧的检测到的2D地标从2D提升到3D。请注意,遮挡的界标会根据帧所属的组自动移除,例如,对于左侧组中的帧,面部右侧的界标将被移除。
3.2 几何生成
3.2.1 初始模型定义
使用基于 PCA 的线性 3DMM 进行参数建模。 人脸模型的形状和反照率纹理表示为:
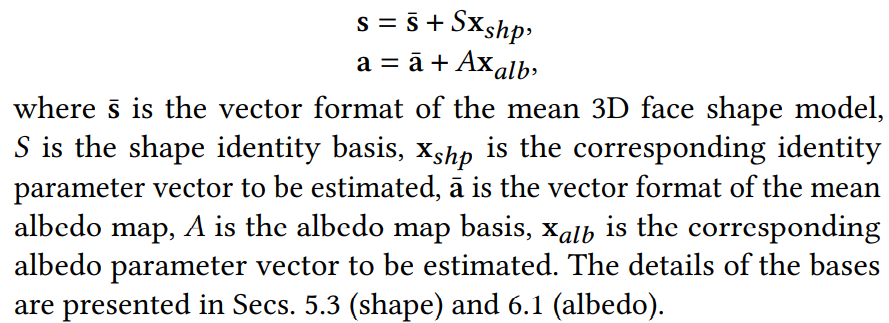
其中 s¯ 是平均 3D 人脸形状模型的向量格式,𝑆 是形状身份基础,x𝑠ℎ𝑝 是要估计的相应身份参数向量,a¯ 是平均反照率图的向量格式,𝐴 是反照率图基础颜色,x𝑎𝑙𝑏是要估计的相关反照率参数向量。
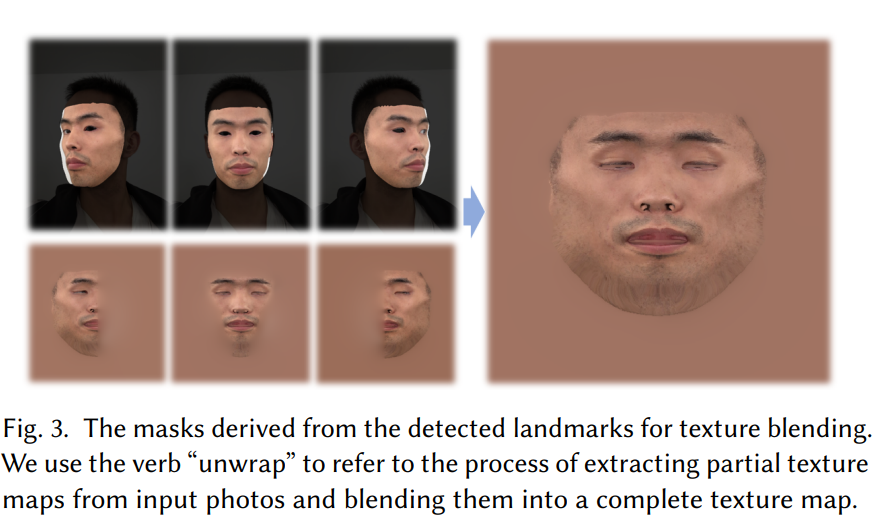
使用岭回归 ,可以通过将形状模型投影到每个输入图像上来提取部分纹理图。 使用从每个视图的地标派生的预定义蒙版(见图 3),然后使用拉普拉斯金字塔混合将部分纹理贴图混合成完整的纹理贴图。(unwarp操作) 初始反照率参数可以通过另一个岭回归来获得,以拟合混合纹理图。
3.2.2 优化框架
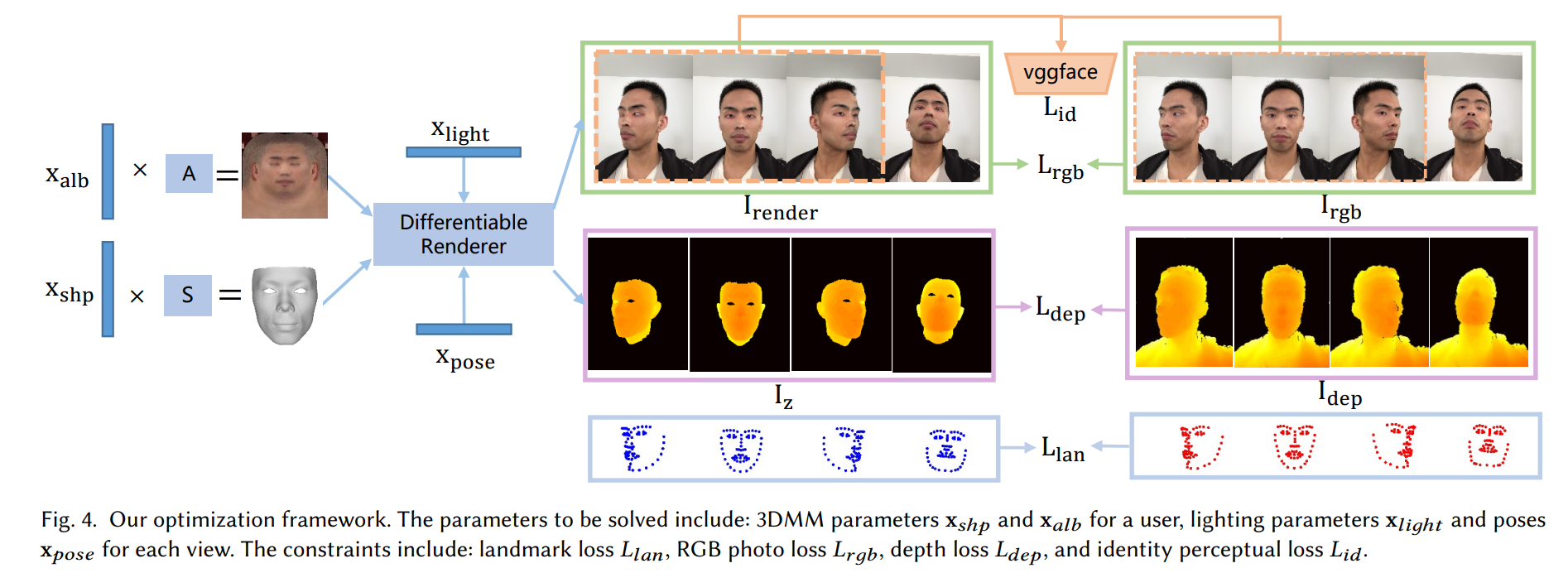
优化框架: 要解决的参数包括:用户的 3DMM 参数 x𝑠ℎ𝑝 和 x𝑎𝑙𝑏,每个视图的照明参数 x𝑙𝑖𝑔ℎ𝑡 和姿势 x𝑝𝑜𝑠𝑒。 约束包括:关键点损失𝐿𝑙𝑎𝑛、RGB 照片损失𝐿𝑟𝑔𝑏、深度损失𝐿𝑑𝑒𝑝和身份感知损失𝐿𝑖𝑑。
优化目标: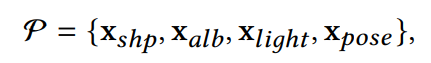
对于每个用户的两个3DMM系数是不同的,而光照系数和姿态系数对每个用户都通用。
目标Loss:
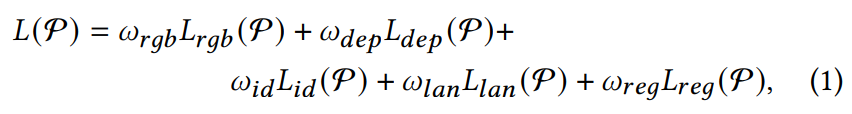
具体Loss:
RGB Photo Loss:L2,输入的RGB图像和渲染的RGB图像做L2



(下图是真实RGB,上图是mesh和贴图在原图上做渲染后的图像)
Depth Loss:L2,ρ是个截断函数,用来限定L2的范围;

Identity Perceptual Loss:L2,过VGGFace的fc7后的特征做感知loss;

Landmark Loss:每个lankmark做L2(不同位置权重不一样)

Regularization:为了确保重建的合理性,对形状和纹理参数应用正则化
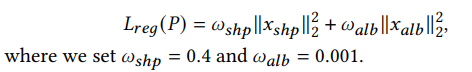
3.2.3 可形变模型的增强(扩充3D数据的方法)
优化中的约束十分丰富(loss很多),如果使用传统的线性3DMM的表达能力十分有限,为此提出了一种增强方法。
motivation:人脸大多不对称,会在对齐人脸模型时造成歧义, 原因是在两个模型的对齐过程中,它们之间的相对旋转和平移是通过最小化模型上某些参考点的误差来确定的。 不同的参考点可能导致不同的对齐结果。 由于人脸的不对称结构,没有完美的参考点。
这提醒我们可以扰乱两个对齐模型之间的相对姿势以获得“代替”的对齐。通过这种方式既可以获得额外的PCA样本,因为新的对齐方式引入了新的变形目标。此外,我们可以使用一组扰动操作,包括姿态扰动、镜像、区域替换等,来增强对齐的模型。 基于生成的大量数据,我们提出了一种随机迭代算法来构建一个 3DMM,将更多的容量压缩到基的更低维度。

数据生成和扰动具体增强步骤(从200个对齐后的面部模型开始)
从 200 个对齐的面部形状模型开始,我们的数据生成和扰动过程包括以下步骤:
1.使用扰动进行区域替换
我们首先用其他模型替换每个模型的鼻子区域,沿俯仰角旋转扰动(在±1度内均匀采样)。 嘴部区域也以相同的方式处理。对于眼睛区域,我们在没有扰动的情况下应用替换。通过在处理过程中最小化引入的视觉缺陷来根据经验设计不同的扰动。 此步骤中使用的面部区域如图 5 所示
2.刚性变换扰动。
然后,我们对每个人脸模型应用刚性变换扰动,其中统一采样范围设置为:沿yam/pitch/roll的 ±1 度用于旋转,沿三个轴中的每一个轴的 ±1% 用于平移 , ±1% 刻度。
3.镜像。
最后,我们沿模型局部坐标系对所有生成的人脸模型应用镜像。 通过这种方式,我们总共得到了超过 100,000 个人脸模型。
最后效果表示,拥有大量数据生成和增强所训练出的模型不出意外有更强大的表达能力,拟合得更好。
迭代增强3DMM构造算法流程:

3.3 贴图生成
这一部分参考博客里讲得很好,建议先看参考博客
提出了一种合成高分辨率反照率和法线贴图的混合方法。
我们注意到基于超分辨率的方法无法产生高质量的眉毛细节。 另一方面,直接合成高分辨率纹理图可能会导致压倒性的细节,这也使得渲染不真实。 我们的方法在基于金字塔的参数表示的帮助下解决了这些问题。 图 9 显示了我们方法的流程。
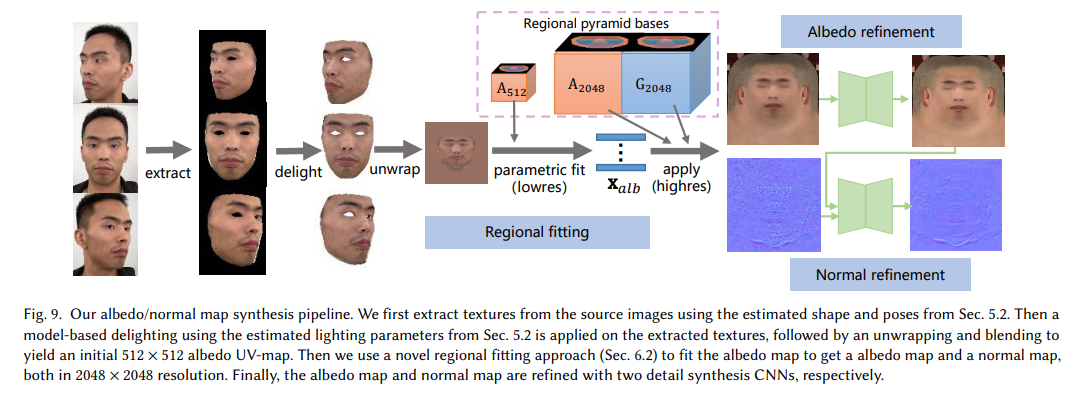
第一步提取纹理(extract)
第二步通过光照参数调整纹理亮度(delight)
第三步将3D人脸展开到2D贴图(unwrap),512*512
unwrap详情见代码,最终效果就是blender里面的展UV
第四步使用区域拟合方法获得2048*2048的反射率贴图和法线贴图(regional fitting)
第五步通过CNN(具体模型为pix2pix)对两个贴图进行细化(refinement)
3.3.1 基于区域金字塔的参数表示构造详解(Regional Pyramid bases)
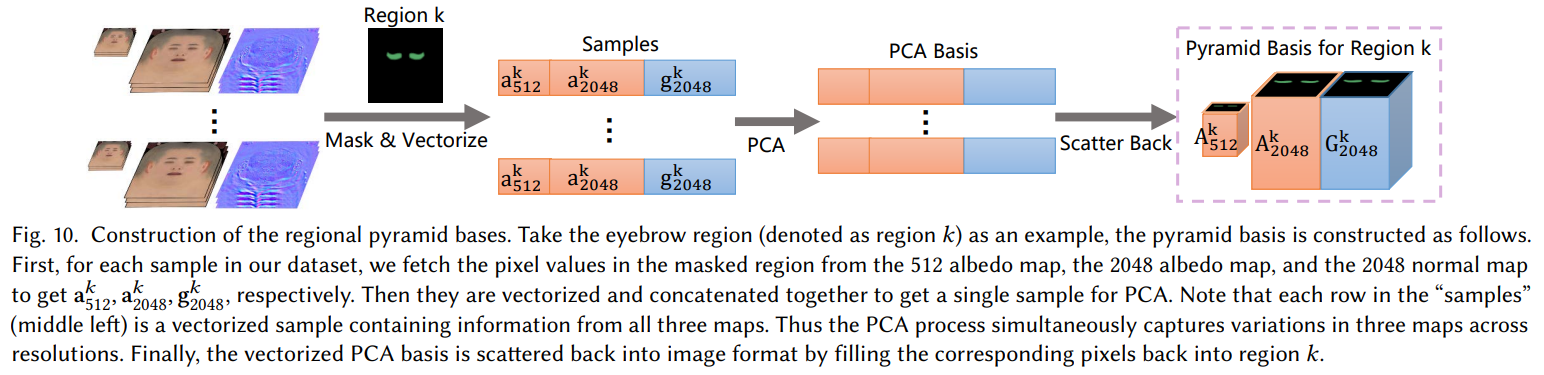
1.先将unwrap后的贴图resize成512和2048大小的图像,最终要得到上图左边的素材;
2.使用Mask将脸部分为8个区域,具体规则如下表示

3.每个样本有三种贴图(512-a,2048-a,2048-g),构成如下三元组

4.concat到一维,计算PCA,得到主成分
5.将得到的主成分根据索引,scatter back回图像
scatter back的操作是tensorflow的scatter_nd()函数实现的。
1 | scatter_nd(indices,updates,shape,name=None) |
根据indices将updates散布到新的(初始为零)张量。
3.3.2 区域拟合(Regional Fitting)
由于构造了regional pyramid base,不同区域的不同类型皮肤/头发细节可以通过高分辨率基分别保存,而低分辨率的拟合过程使算法专注于主要的面部结构,例如,形状眉毛和嘴唇。(多尺度)
区域拟合分为两部分:参数拟合和高分辨率贴图合成
参数拟合
参数拟合部分,就是将生成头模的时候生成的粗略化的Xalb,通过最小化loss,迭代训练得到较优的Xalb。
参数拟合部分只使用了512的贴图
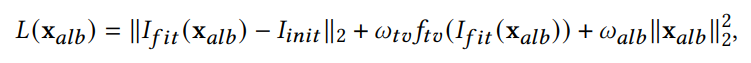
变量解释:
Loss 1
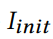 为unwrap后的图像;
为unwrap后的图像;
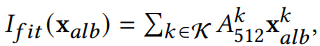 表示将生成头模过程中生成的粗略的颜色贴图参数,与region pyramid bases逐区域相乘拟合再叠加成一张总的颜色贴图;
表示将生成头模过程中生成的粗略的颜色贴图参数,与region pyramid bases逐区域相乘拟合再叠加成一张总的颜色贴图;
然后计算这两张图像之间的L2,记作loss1;
Loss 2
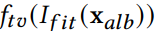
主要消除8个区域边界中的伪影。做法是:通过uv_mask将整个颜色贴图分割成边界mask和非边界mask,然后分别计算颜色贴图中的边界距离和非边界距离,将这两种距离相加。记做loss2;
Loss 3
对于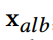 这个颜色贴图参数做L2正则,记作loss3;
这个颜色贴图参数做L2正则,记作loss3;
三个Loss相加 使其最小化,迭代更新颜色贴图参数Xalb,直到得到训练好的Xalb。
高分辨率贴图生成
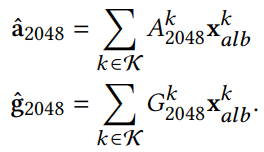
将上部分得到的较优的Xalb,分别与区域金字塔生成的A2048(2048* 2048分辨率的颜色贴图基)逐区域相乘拟合再叠加成一张总的颜色贴图,这便是区域拟合部分得到的最终的颜色贴图。
将上部分得到的较优的Xalb,分别与区域金字塔生成的G2048(2048* 2048分辨率的法线贴图基)逐区域相乘拟合再叠加成一张总的法线贴图,这便是区域拟合部分得到的最终的法线贴图。
细节生成
基于pix2pix模型,进出模型的分辨率是相同的,但细节上会细化;
在训练过程中,首先使用面部区域替换和肤色转移将200幅高质量反照率/法线图(来自构建3DMM的数据集)放大为4000幅图,作为训练两个网络的GT。
然后,对4000幅图执行区域拟合(Regional Fitting),以获得拟合的反照率/法线地图,这些图在训练期间用作网络的输入。只使用整个UV贴图中的面部区域来计算训练损失。
类似于pix2pix,保持𝐿1损耗和GAN损耗。对于反照率细化,我们还应用总变化损失(total variation loss)来减少伪影并改善皮肤平滑度。对于法线图细化,还使用预测和GT图之间的逐像素余弦距离,以提高正常方向的精度。使用Adam优化器对网络进行75000次迭代。