《Geometric and Textural Augmentation for Domain Gap Reduction》
paper: Geometric and Textural Augmentation for Domain Gap Reduction (thecvf.com)
code: xch-liu/geom-tex-dg: Geometric and Textural Augmentation for Domain Gap Reduction (github.com)
任务
通过纹理和风格分布采样增强训练数据提升不同风格不同形变物体识别效果。
出发点
对于艺术品这种具有风格形变的目标识别性能不好;
有工作人为这是个域泛化的问题,但已被证明的是:同一个类别但不同样式的数据往往比不同类别但相同样式的数据的差别更大,从而阻碍常规的DG方法;
此外,照片和艺术品的数量也不尽相同。因此,从几乎完全由照片组成的训练数据转移到包含艺术品的测试集是一个重大挑战。
最近的工作集中于通过style transfer应用于训练示例来提高模型鲁棒性,减轻过拟合;
理由为:通过输入不同风格纹理的图像数据,从而使得识别网络被迫关注于物体本身语义特征的学习,如形状等
但大多数仅关注于纹理的迁移,而忽略了几何形变的迁移;
创新点
在几何和纹理风格方面弥补了domain的差距,而不仅仅是纹理;
本文的增强过程不同于现有技术,当前的文献通过使用一组(纹理)风格的样本将照片处理成不同风格艺术品来扩充数据集,相反,本文构建纹理和几何描述符的独立分布,并从中采样以增加训练数据。我们的实验表明,几何和纹理增强提高了几种常见跨域基准的分类泛化能力。
idea概览
本文假设纹理style和对象身份是独立的;(类似 content 和 style 的概念)
同一身份类别中的图像的扭曲场一般是相似的,而跨身份类别图像的扭曲场存在显著差异;

手写数字和马的扭曲场明显是不一样的,
样式包括纹理和几何。纹理样式与对象类无关:知道图片是水彩或剪贴画并不能预测其对象类(身份类别)。不过,几何样式取决于对象类。使用learning to warp(箭头上方的颜色编码扭曲字段和下面相应的变形结果),可以扭曲显示相同对象类但纹理样式不同的源图像。可以看到,对象类中的扭曲场是相似的,但在对象类之间差异很大,马和文字的扭曲场(可视化表示为图中的热力图)明显不一致。
做法
增强通过处理训练输入x来扩展训练数据,以生成新的训练输入A(x)。分为两个步骤:几何增强扭曲图像;纹理增强变更纹理。
这两步通过独立采样两个分布来执行,分布构建是采用预先训练好的特征提取器。
图示训练集S包含3种风格3个类别
本文目标为学习一个预测模型,能够很好地泛化到一个unseen style domain,也就是说,使用训练集S构建一个分类器,当图像的style是unseen的时候也能表现得很好。
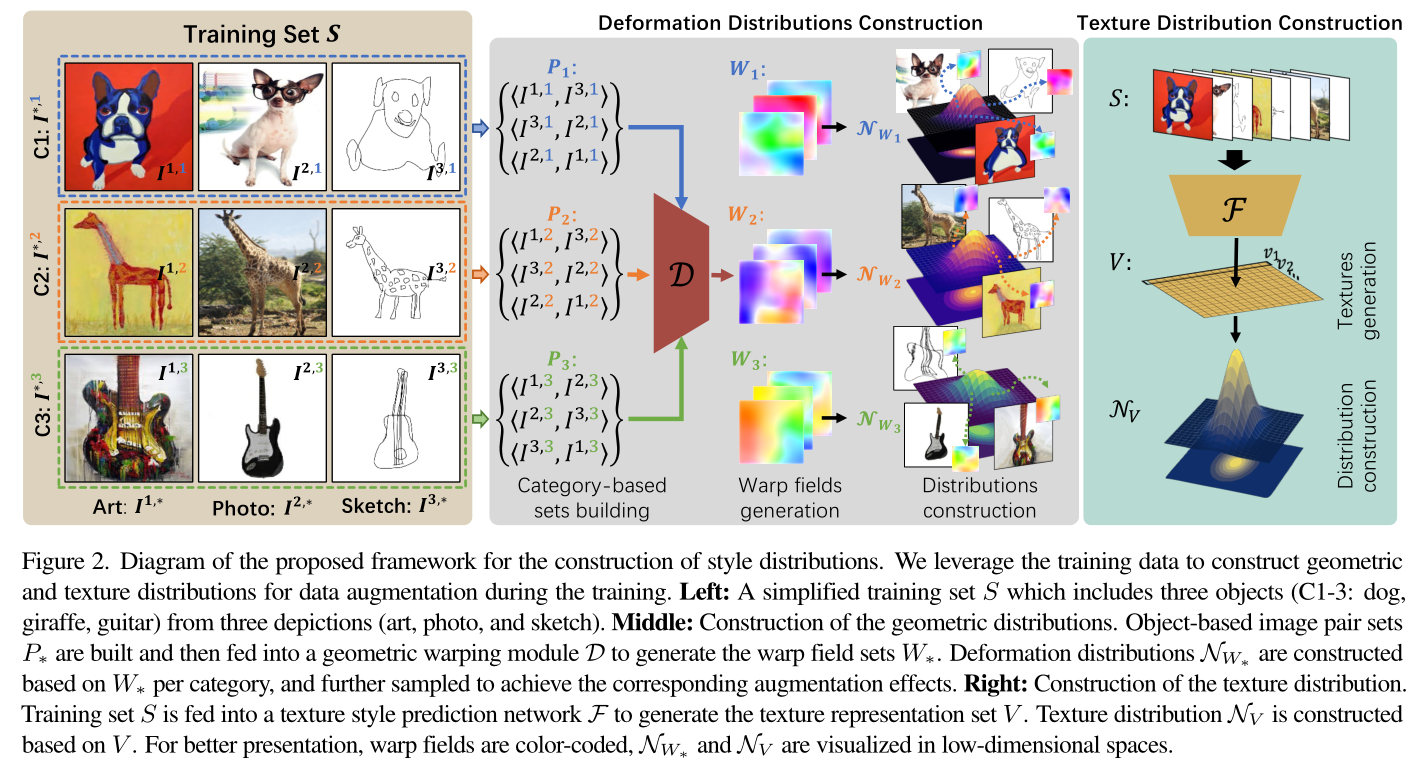
本文默认同一个身份类别的图像有着相近的扭曲场;
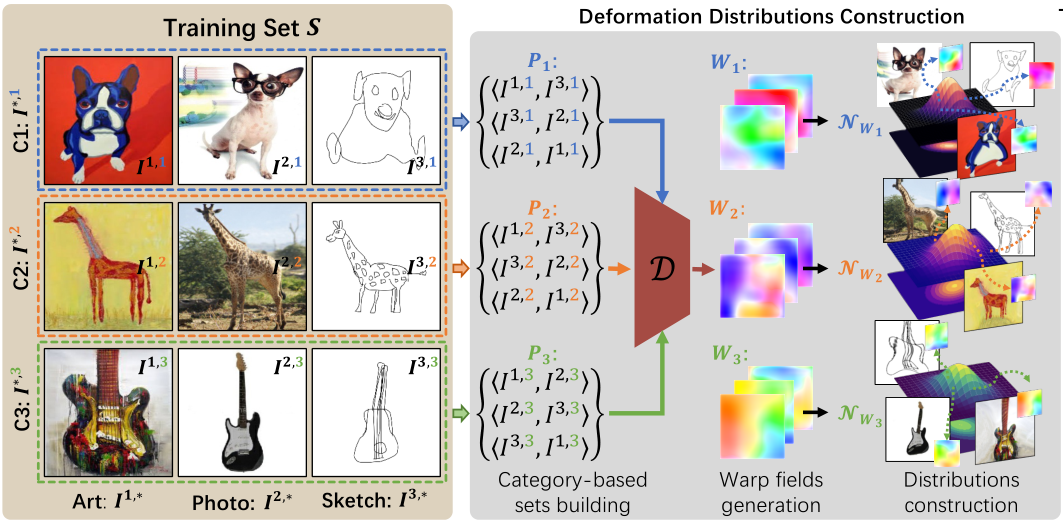
左:一个简化的训练集,包括三个风格(艺术、照片和素描)中的三个对象(狗、长颈鹿、吉他)。
中:输入同一身份不同风格的图像进行排列组合构成图像对,图中是三种就构建了三种排列组合;然后送入扭曲模块,生成warp field W*;
扭曲分布NW 就由每个身份类别的扭曲场 W 构建,并从这些分布中采样扭曲原本的图像,以达到增强效果;**
右:纹理分布的构造。将训练集输入纹理样式预测网络F以生成纹理表示集V。纹理分布NV是基于V构造的。为了更好地显示,扭曲字段采用颜色编码,NW∗和NV在低维空间中可视化。
几何增强
几何增强是通过对训练数据进行随机形变来实现的。每个随机形变都要有以下的几个要求:
(1)形变速度要足够快,以便再训练期间在线执行;
(2)形变程度要可控,以避免过度形变;
(3)最重要的是,形变的类型应该足够丰富,来确保可变性并且足够合理,以避免无意义和误导性的形变(应符合特定的身份类别——比如马不能按照狗形变)
本文使用了《Learning to Warp》(见上个markdown)的warper来实现上述效果;
具体操作:
例如一个类别 k 中有N张图像,那这N张图像排列组合成所有的图像对,每种图像对都对应了一个的扭曲场,每个类别的扭曲场又构成一组扭曲场;

如何将这些扭曲场施加到训练图像上呢?
如果直接从Wk(一组扭曲场)中采样,那么扭曲的样式数量就由K的大小限制住了,为了使本文的方法能够支持尽可能广泛的几何样式,基于Wk构造了一个几何分布,并直接从中采样新的扭曲场。
使用多元正态分布对扭曲分布进行建模,计算均值和协方差矩阵:

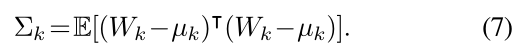
Wk表示为一个二维的矩阵,每一列代表一个 “矢量化” 的扭曲场。
为减少计算均值和协方差矩阵的计算量,对Wk做了一步下采样操作。
纹理增强
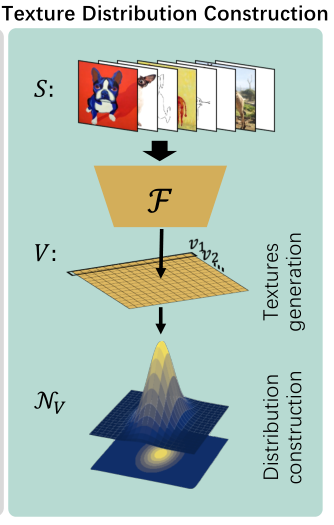
采用Ghiasi的《Exploring the structure of a real-time, arbitrary neural artistic stylization network》,模型代码位置Dassl\dassl\modeling\backbone\styleaugment\styleaug\ghiasi.py
具体细节:
模型具体的两个模块:
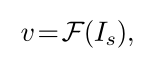
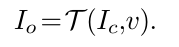
通过一个纹理样式预测网络,从一个style图像预测一个100维的向量v,(trained on PBN数据集);
这些向量组成一个矩阵;
使用多元正态分布对扭曲分布进行建模,计算均值和协方差矩阵(同扭曲分布的构建),不同之处在于,由于纹理央视和对象类的假设是独立的,可以将类别和域标签融合在一起(不细分类别,所有训练数据一起构建);
在做纹理增强时,在Nv分布中随机采样v,并通过样式预测网络传输v,再再content图像Ic上来应用这个采样出的纹理v得到Io;
为了控制风格增强的程度,做了个线性插值:
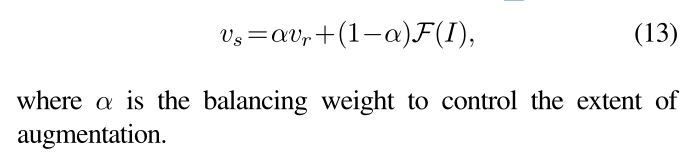
除了增强纹理样式表示之外,上述方法的另一个好处是计算效率。通过对图像进行批处理来构造纹理分布(一个batch先构造好?),然后进行直接表示采样,可以大大减少训练过程中的时间开销。
结合几何和纹理增强
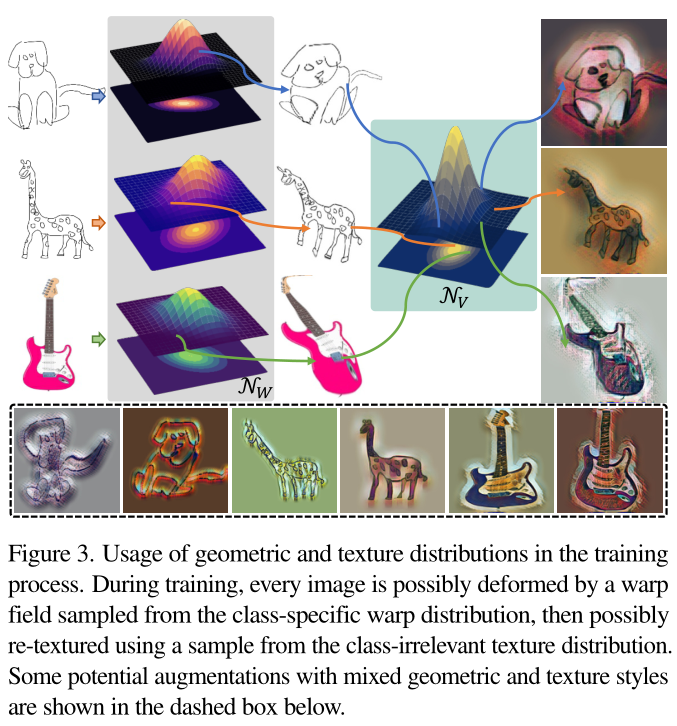
在训练过程中使用几何和纹理分布。在训练过程中,每个图像都可能被从特定类的扭曲分布中采样的扭曲场变形,然后可能使用来自与类无关的纹理分布的样本重新纹理。下面的虚线框中显示了混合几何和纹理样式的一些潜在增强。
实验
在本节中,我们将评估我们的方法在几个基准上的性能,并将其与最新的最先进的方法进行比较。我们还进行了烧蚀研究,以验证我们的识别方法中每个成分的重要性,无论描述风格如何。在每一种情况下,被测试的假设都是,增强通过扩大视觉对象类(VOC)以包括看不见的示例来增强对象分类性能。因此,我们不对任何测试图像应用任何类型的增强:我们的假设是VOC足够宽,可以包含新图像。
具体数据见代码文件组织结构。
做了多源和单源的域泛化效果对比。
结论
结论1:
从实验效果可知纹理和几何变换都有效,纹理影响更大;
证明了:纹理偏移大于几何偏移。根据我们的实验结果和之前一些研究的发现,这种现象可能有一些原因:
这与CNN对非形状特征的敏感性有关。CNN对范围广泛的图像处理非常敏感,对人类判断几乎没有影响。
具有纹理偏好的CNN可能表示归纳纹理偏差,这使得模型很难在小数据区域中学习几何相关特征,也很难将其推广到不同的分布,而不是它们所训练的分布。
结论2:
我们的实验结果还表明,几何和纹理增强的效果因数据集而异。最大的原因之一是数据集之间的对象和样式差异。
一些对象类本身具有几何形状差异,例如PACS中的动物和数字DG中的手写数字。相比之下,Office Home中的静态对象具有较少的类内形状变化。这意味着它们对几何样式的依赖不同。
(几何扭曲越多的数据集,几何增强影响越大)
局限:
由于我们的几何和纹理分布是基于源图像的相应特征表示构建的,因此它们强烈依赖于图像质量。如果特征表示远远不够好,则扩充空间将是次优的。
补充:
此外,对于不同的任务,如场景级分类、多对象图像,我们的纹理增强是适用的,但几何增强不能直接使用,因为它可能会在不考虑场景内容的情况下引入扭曲。一种潜在的改进方法是增加场景中的单个对象,这反过来需要对象检测,这是一个与分类不同的研究领域。这超出了本文的范围,但却是一个很好的未来探索方向。