《IACycleGAN》
paper: Identity-Aware CycleGAN for Face Photo-Sketch Synthesis and Recognition (arxiv.org)
code: none
任务
真人素描生成与识别
出发点
生成促进识别 识别促进生成;
大部分生成方法使得合成图像与原始图像在纹理上保持一致,会导致信息丢失;
大多数生成框架都只能学习两个域之间的关系,其鉴别器只关注照片和草图之间的差异,而不考虑任何特定的识别优化(身份信息);
创新点
在CycleGAN上加入了感知损失(perceptual loss),能更好的关注面部的语义信息(眼睛、鼻子);
使生成模型和识别模型相互优化,生成模型迭代生成更好的图像,Triplet Loss训识别模型;
做法
生成模型
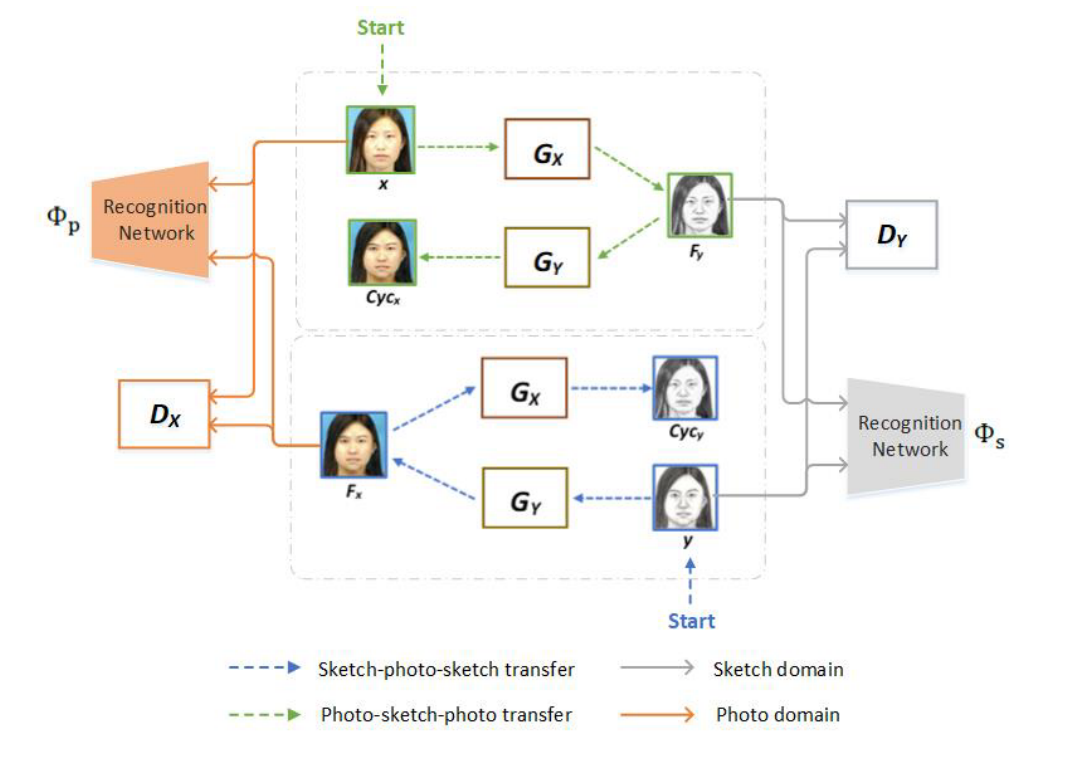
分别给出两个domain的照片(这里输入的是paired数据,这里的paired应该身份paired),其训练目的是获得Gx,Gy两个生成器。
两个识别网络,其目的是使用pretrain好的vggface提取feature做Identity perception loss;
生成器用了《Perceptual losses for real-time style transfer and super-resolution》中的结构;
判别器用了PatchGAN的结构;
生成网络整体loss图示
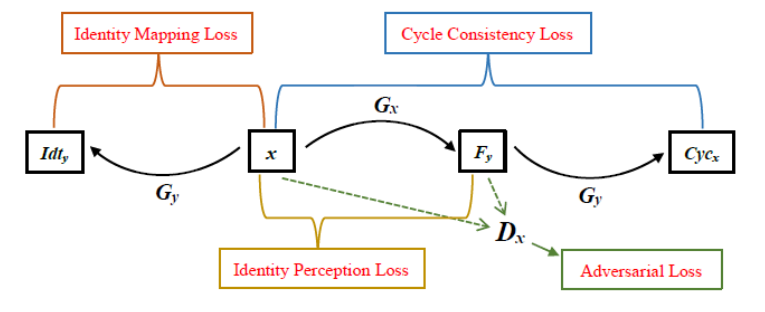
对抗损失(adversarial loss)
输入图像与生成图像进入判别器进行计算,最小化下式
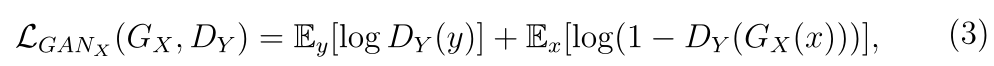
循环一致性损失(cycle consistency loss)
Gx生成的图像再进入Gy恢复原本domain与最初的输入x计算L1,此loss为pix级,最小化下式
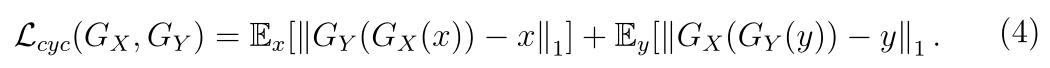
身份保持损失(identity perception loss)
仅使用对抗损失会导致伪影和训练不稳定,需要加更强大的监督;
通过一个pretrain的识别网络(文中选择vggface)分别提取两对(原图与合成图)的feature计算L2,此loss区别于pix级监督,是feature级,文中对于此处的解释是:绘制的草图会有夸张成分以扭曲面部纹理信息,夸大面部特征,完全基于pix重建图像效果不会好;CycleGAN的训练需要进行数据增强操作(resize,flip等)难以实施pix级的监督。
最小化下式
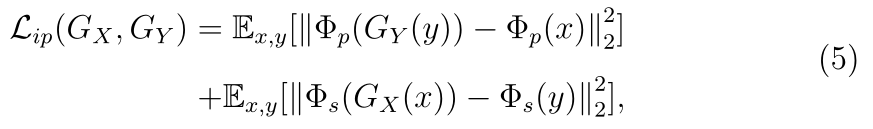
身份映射损失(identity mapping loss)
常规的pix级的约束,最小化下式
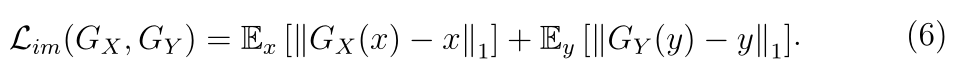
整体loss
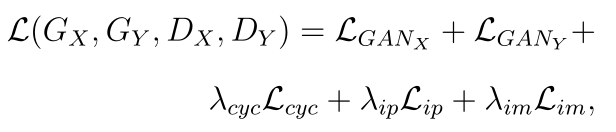
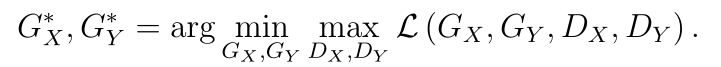
最小化生成器的loss最大化判别器的loss
其中超参数lamda分别设为10,30000000,5
识别网络与生成网络的互相优化
许多主做生成的工作都是fix相应的识别网络作为一个特征提取器来附加身份保持损失;
本文的做法估计是:
step1:先fix识别网络参数训练生成网络,获得一定量的生成的图片;
step2:使用生成的图片fine-tune识别网络(单走一个人脸识别模型的流程),用了triplet loss,更新识别网络参数,其中两个模态分别有两个识别网络,要分开训练;
step3:重复上述操作以获得更好的生成模型和识别模型。
(有问题的点:若第一次生成的质量得不到保证,那低质量的生成图像真的能提升识别模型的acc吗?互相优化的模型很依赖第一次生成的图像质量)
我认为的做法:先简单训练一个识别网络达到一个还行的acc,更新其backbone参数作为生成网络的特征提取器,然后再进行生成网络的训练。
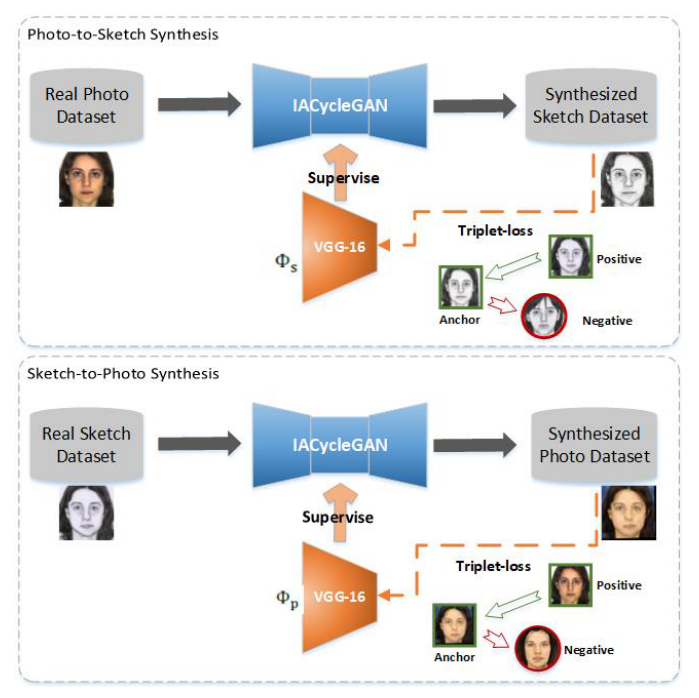
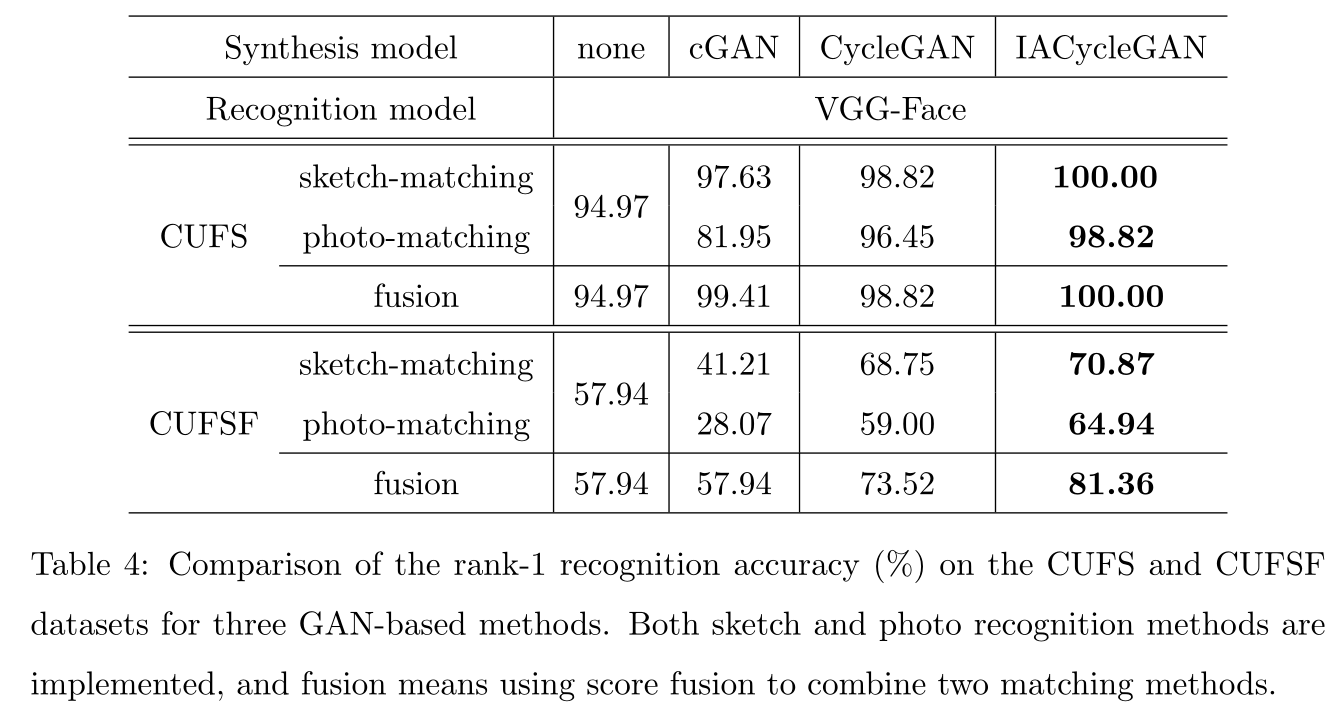
实验
CycleGAN生成—》一阶段vgg fine-tune—》IACycleGAN生成(加入fine-tune的vgg提取的特征做身份保持损失)—》二阶段vgg fine-tune
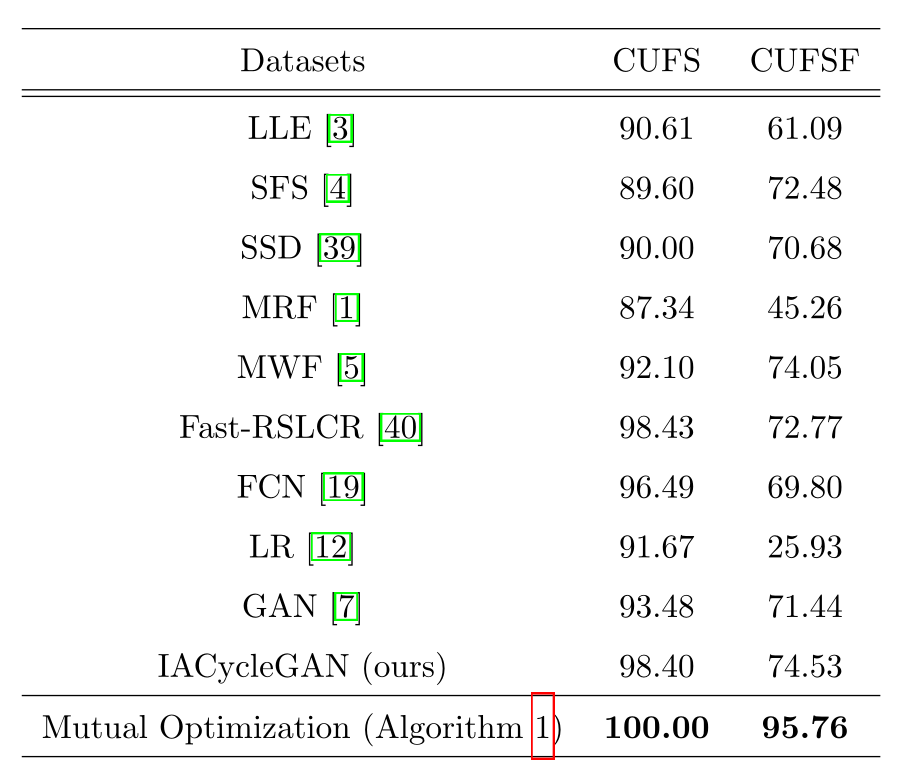
数据集
CUFS和CUFSF
生成模型实施细节
对于生成网络的训练,都是从头开始训练,使用instance normalization来实现更好的稳定性和更低的噪声;
使用Adam优化器,horizontal filp prob=0.5用于数据增强;
前100个epoch设置0.0002的学习率,并在后100个epoch线性下降至0;
在titian xp上训练了10小时;
为减小网络震荡,采用存储多个生成图像的图像缓冲区来更新鉴别器,而不是使用最后生成的图像。
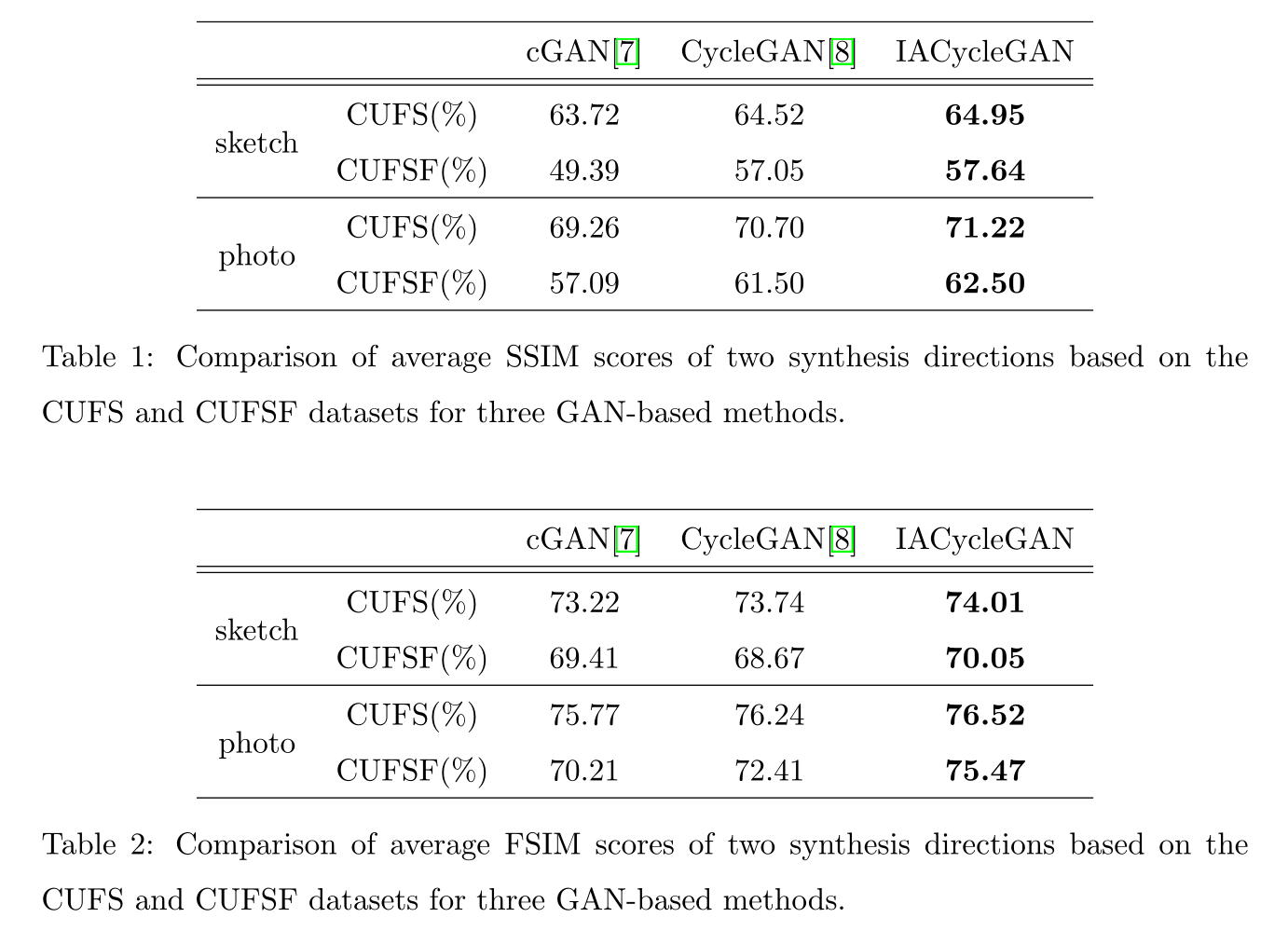
生成使用了SSIM FSIM两个指标
识别模型实施细节
文中用的vggface,caffe上跑的(估计是官方代码)
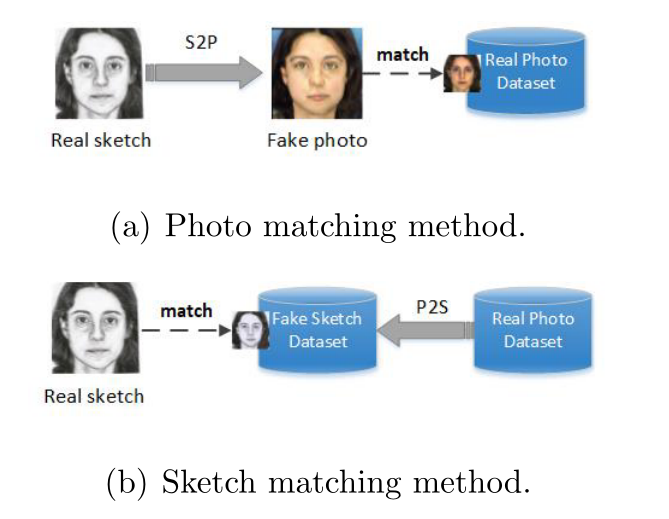
在做检索任务时,先做风格模态的迁移,再计算相似度。