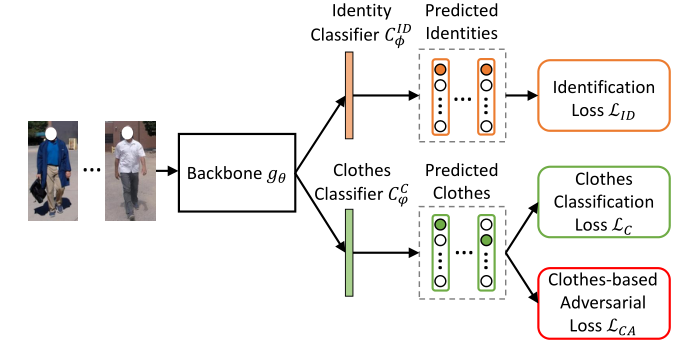
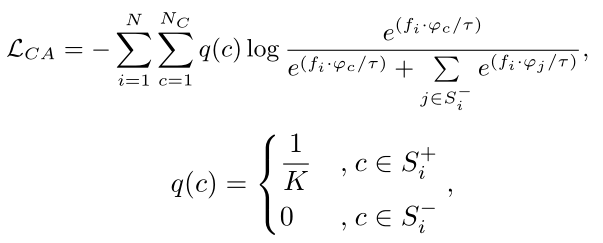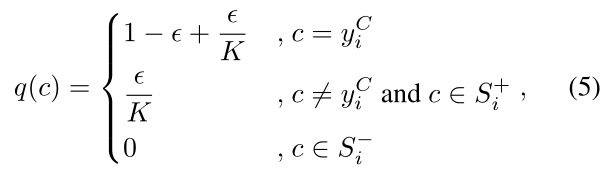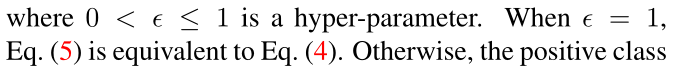def forward(self, inputs, targets, positive_mask): """ Args: inputs: prediction matrix (before softmax) with shape (batch_size, num_classes) targets: ground truth labels with shape (batch_size) positive_mask: positive mask matrix with shape (batch_size, num_classes). The clothes classes with the same identity as the anchor sample are defined as positive clothes classes and their mask values are 1. The clothes classes with different identities from the anchor sample are defined as negative clothes classes and their mask values in positive_mask are 0. """ inputs = self.scale * inputs negtive_mask = 1 - positive_mask identity_mask = torch.zeros(inputs.size()).scatter_(1, targets.unsqueeze(1).data.cpu(), 1).cuda()