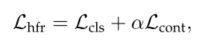《DVG-Face:Dual Variational Generation for Heterogeneous Face Recognition》
paper: 2009.09399.pdf (arxiv.org)
code: BradyFU/DVG-Face: DVG-Face: Dual Variational Generation for Heterogeneous Face Recognition, TPAMI 2021 (github.com)
出发点
为解决异构人脸识别(Heterogeneous Face Recognition)问题中成对异构数据匮乏的问题。
创新点
将异构人脸识别视为一个双生成(dual generation)问题,从噪声中采样大规模的成对异构人脸数据;
将丰富的身份信息集成到联合分布中,以丰富生成数据的身份多样性。同时,对生成的成对图像施加一个保持成对身份的损失(pairwise identity preserving loss),以确保它们的身份一致性。这两个特性使得能够更好地利用生成的未标记数据来训练异构人脸识别网络;
通过将生成的成对图像视为正对,将从不同样本获取的图像视为负对,通过对比学习对异构人脸识别网络进行优化,以学习domain-invariant和区分性的embedding feature。
与前作DVG的不同
生成图像的身份更丰富:
对于前作,生成器只能使用小规模的成对异构数据进行训练,从而限制生成图像的身份多样性。在当前版本中,重新设计了生成器的体系结构和训练方式,允许使用成对异构数据和大规模未配对VIS数据(单模态的非成对真实人脸数据)对其进行训练。后者的引入极大地丰富了生成图像的身份多样性。
生成的图像被更有效地利用:
前作借助身份一致性属性,通过成对距离损失(pairwise distance loss)使用生成的成对数据对异构人脸识别网络进行训练。在此基础上,得益于上述身份多样性特性,当前版本进一步将从不同样本中获得的图像视为负对,形成了一种对比学习机制。 先前版本只能利用生成的图像来减少域差异,而当前版本则利用生成的图像来学习域不变和区分性嵌入特征(可学习)。
增加了更深入的分析和更多的实验:
增加不同模态对图像的实验。
前备知识
VAE
变分自编码器(VAE)原理 - 知乎 (zhihu.com)
做法
待解决问题:
(1)如何生成不同的配对异构数据
(2)如何有效利用这些生成的数据
Dual Generation
核心:结合域属性和身份特征
通过一个双变分生成器实现。生成器包含两个特定域的encoder(图中的橙色和灰色Ev,En),一个decoder(浅蓝色G),一个预训练好的人脸识别网络(F)以及一个身份采样器(Fs)。
两个Domain-specific attribute encoders用于学习NIR和VIS数据的领域特定属性分布,人脸识别网络用于提取身份特征,身份采样器可以灵活地从噪声中采样丰富的身份表示(?)。成对异构数据的联合分布由身份表示和属性分布组成(具体的fusion文中并未指出,代码中是concat),decoder将联合分布映射到像素空间。
Training with Paired Heterogeneous Data
输入成对同身份的异构图像,生成器学习潜在空间中的解耦联合分布。具体而言,采用在MS-Celeb-1M上预训练的人脸识别模型(本文采用的是LightCNN)作为特征提取器,由F提取出的特征被认为仅仅是identity related。考虑到F是从VIS模态预训练得到的,在另一个模态的表现不好,那么只需要提取VIS模态的身份特征作为两个模态共同的身份表示。
两个encoder提取出Domain-specific attribute分布,为确保其仅仅是属性相关的,在属性和身份表示之间施加了角度正交损失。最后解耦后的两种分布构成成对NIR-VIS数据的联合分布,然后被送到decoder作为输入。
该过程中涉及到了四个损失函数:包括角正交损失、分布学习损失、成对身份保持损失和对抗性损失。
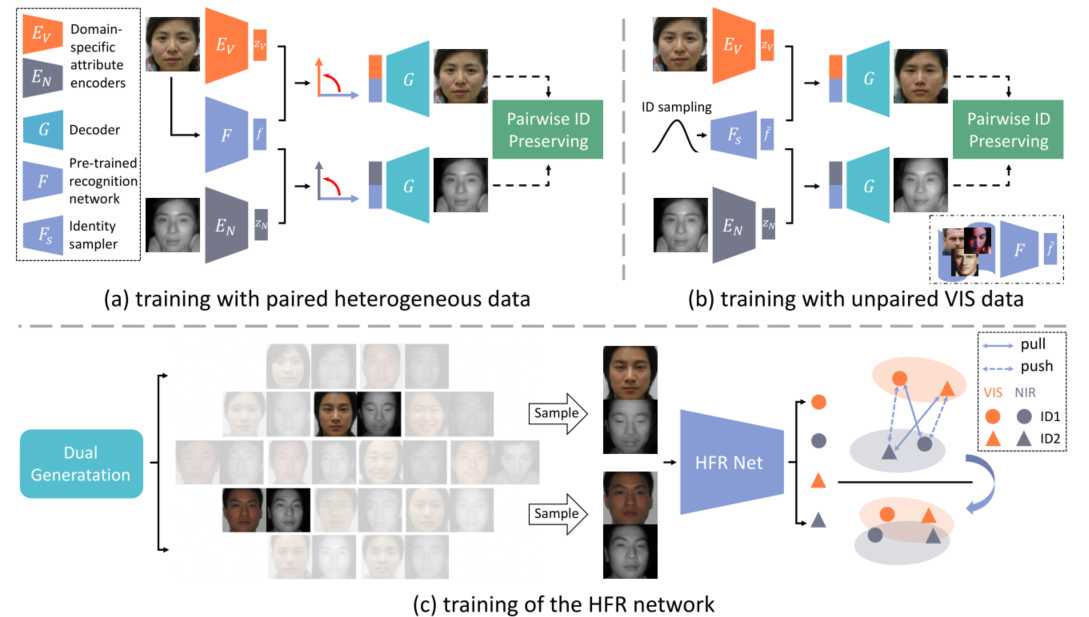
Angular Orthogonal Loss
角正交损失施加在Zv和f,Zn和f之间,计算它们之间的余弦相似度,最小化他们的绝对值的和。
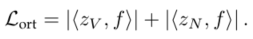
Distribution Learning Loss
分布学习损失启发自VAEs,首先用KL散度计算两个分布的差异,再结合L1正则化重构decoder的输入。
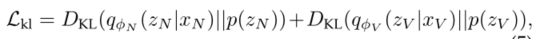
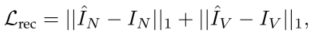
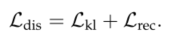
Pairwise Identity Preserving Loss
为了保留生成数据的身份,以前基于条件生成的方法通常采用身份保留损失。利用预训练好的人脸识别网络分别提取生成数据和真实目标数据的嵌入特征,然后迫使这两个特征尽可能接近。然而,由于既不存在类内约束,也不存在类间约束,因此很难保证生成的图像属于与目标一致的特定类。
本文关注生成的成对图像的身份一致性,而不是生成的图像属于谁。因此提出了一种成对的身份保持损失,以限制特征之间的距离
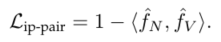
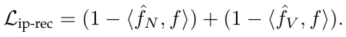
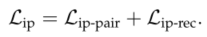
Adversarial Loss
引入对抗损失来提高生成图像的清晰度。
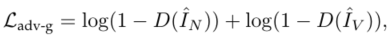
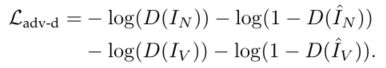
Overall Loss
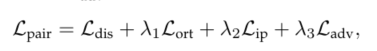
Training with Unpaired VIS Data
身份信息获取的一种简单的方法是使用预训练的人脸识别网络从大规模VIS数据中提取身份。然而,如果希望在测试阶段生成大规模的新配对数据,必须拥有相同数量的具有不同身份的VIS数据(如b图右下角)。
为避免此情况,引入了身份采样器(identity sampler)。具体实现为,首先采用识别网络提取MS-Celeb-1M数据集上的embedding特征,利用这些特征来训练VAE模型。训练后的VAE的decoder被用作身份采样器,它可以将标准高斯噪声中的点映射到身份表示。
由于这些采样的身份表示没有对应的ground true异构图像,本文建议以不成对的方式训练生成器。
整体流程:
首先,通过身份采样器Fs对身份特征f~(经过识别网络提取)进行采样。
然后,将两种属性分布特征Zn和Zv以及f~分别concat输入decoder G。
最后,生成一对不属于异构数据库的新异构图像。
其中的loss和train with paired的情况类似,只不过没有了对抗损失(具体可见train_generator.py代码中的loss部分)。
Heterogeneous Face Recognition
与训练好的LightCNN作为backbone,使用有限的数据对进行训练,再使用大规模生成后的数据进行训练对比。loss选择softmax loss。backbone在训练生成器时是权重更新的,在此处HRN中固定。
对于生成的数据,由于没有特定的类别标签,上述softmax loss不适用。引入对比学习机制来利用这些数据。
对比学习机制流程:
首先从生成数据中采样两对异构数据,基于生成的都是身份一致的,这两对都是正例,再将其做交叉,构造出了两对负例,要注意的是要保证交叉后的模态还是跨模态的。对比损失如下:
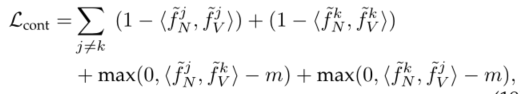
其中m是一个margin值。
整体的HFR网络损失为: