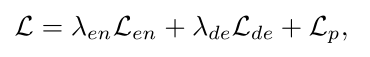《Pose-guided Feature Disentangling for Occluded Person Re-identification Based on Transformer》
paper: https://arxiv.org/pdf/2112.02466v2.pdf
出发点
存在遮挡的行人重识别(Occluded Person Re-identification),由于遮挡的存在,各种噪声被引入,导致特征不匹配;遮挡可能具有与人体部位相似的特征,导致特征学习失败。
前人的方法有:使用姿势信息指导特征空间将全局特征划分为局部特征(缺点是需要严格的特征空间对齐);使用基于图的方法建模拓扑信息(缺点是容易陷入上述的第二种问题)。
创新点
本文探索了在没有空间对齐的情况下,将附加姿势信息与Transformer相结合的可能性。其使用姿势信息对语义成分(如人体的关节部位)进行分解,并对非遮挡的部位进行选择性匹配;设计了一种Pose-guided Push Loss。
做法
整体框架图:
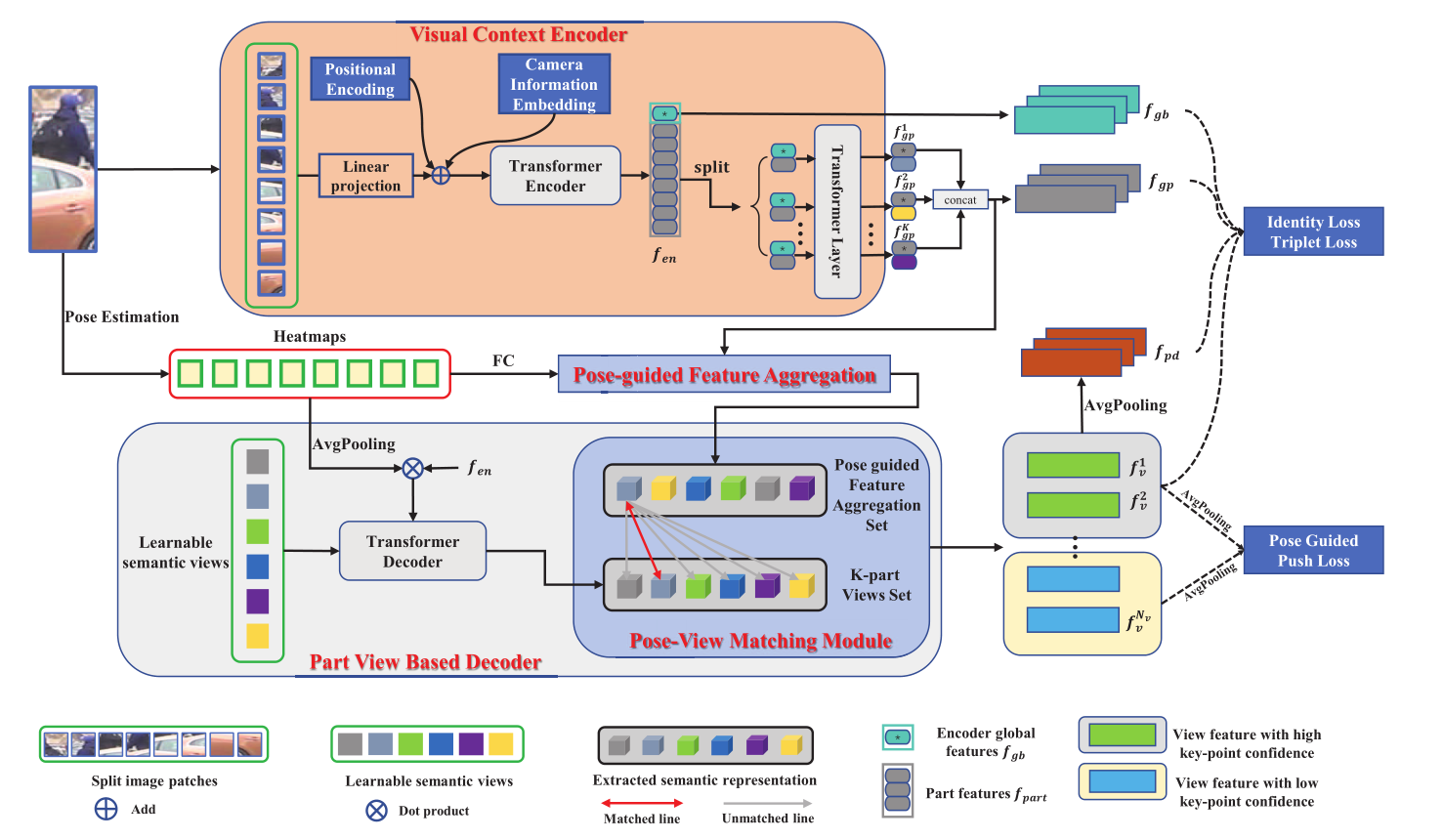
Visual Context Transformer Encoder
首先需要对输入图像划分为固定大小的N块patch,步距大小定义为S,每块patch的尺度定义为P,patch个数N为:
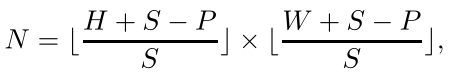
当S等于P时,划分出来的patch就不重叠;当S<P时,patch重叠,可以减少空间领域信息的丢失。
将这些patch通过线形层生成一个序列输入transformer encoder,concat一组可训练的Position Encoding,以及Camera Information Embedding(表示该图像所属的摄像头视角信息,标签给定的,相同视角图像有一样的值),最终的输入序列定义为:
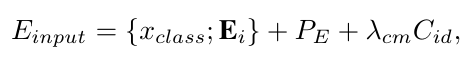
最后通过Transformer Encoder输出分为两部分的特征,一部分为global feature,一部分为part feature。为进一步区分人体各个部位的特征,part feature又分为K组,每一组都与global feature做cancat送入shared transformer layer学习这些K组融合特征。
Encoder Supervision Loss
选用交叉熵损失作为identity loss以及triplet loss来作为这部分的loss:
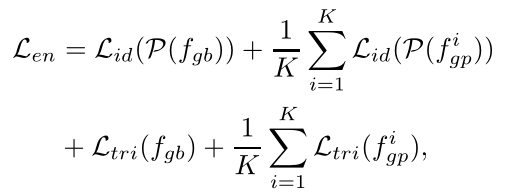
Pose-guided Feature Aggregation
被遮挡的人体图像的身体信息较少,而非身体部位的信息可能不明确。本文使用pose estimator 从图像中提取landmark信息。
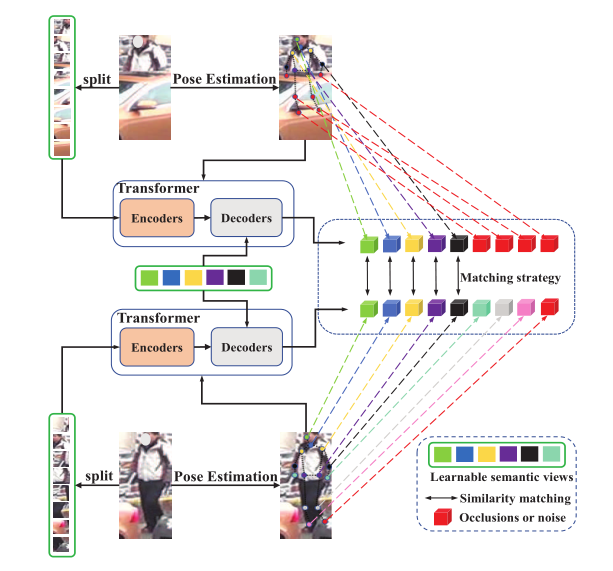
Pose Estimation
给定一张图像,估计器从中提取M个landmark,然后利用这些landmark生成一组heatmap H,每张heatmap都被下采样到(H/4)*(W/4),其中最大的response point对应一个joint point,设置了一个阈值γ来滤除高置信度和低置信度的landmark。滤除出的剩余landmark的heatmap并不是将其设为0,而是赋值0/1,热图标签可以形式化为:
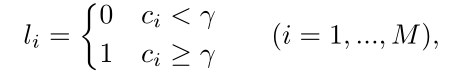
ci定义为第i个landmark的置信度分数。
Pose-guided Feature Aggregation
将之前的分组数设为K=M,使其等于landmark的数量。将生成的一组heatmap H后接一层FC,使其尺寸与group part local feature(fgp)相同,得到H‘。将H‘与fgp mutiply element-wisely(向量对应元素相乘,将heatmap的注意力附加在fgp上)获得P,其目的是为了从fgp中找到对身体某个部位贡献最大的信息部分。
为此,本文开发了一种匹配和分布机制,将part local feature和pose-guided feature视为一组相似性度量问题,最终获取一个pose-guided feature集合S。
对于每个Pi,在fgp中找到最相似的特征,即找寻融合了heatmap注意力的序列和原始局部特征的最近距离的局部特征,以选出优质的局部特征,用余弦距离,形式化定义为:
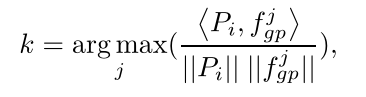
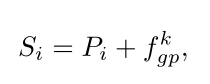
Part View Based Transformer Decoder
将heatmap和fen做点乘送入Decoder学习一系列learnable semantic views以学习有区别的身体部分。其实整个框架的大体思路为一张图片走两路,一路分patch进transformer encoder,一路特征点检测生成heatmap走transformer decoder,再将这两部分的输出进行match,可以得到view feature,取高置信度的view feature采样成与fgb,fgp相同尺寸算triplet loss,再将所有的view feature采样做Pose Guided Push Loss。
Pose-View Matching Module
此部分计算patch view和通过Pose-guided Feature Aggregation得到的Set之间的相似度,来获得最终的view feature,用余弦距离,形式化定义为:
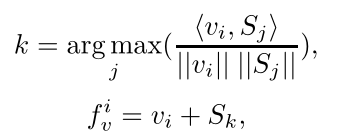
之前的heatmap通过阈值打好了0/1标签,最终的view feature即可通过heatmap标签分为两类。在上述距离置信度较高的view feature中取heatmap label为1的;在置信度较低的view feature中取heatmap label为0的。这样的操作会产生可变长度,需要固定长度补0操作。
Decoder Supervision Loss
提出的Pose-guided Push Loss:
余弦距离:
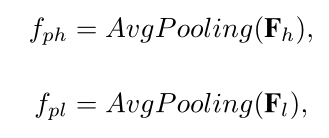
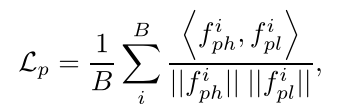
整体的loss定义: