《Sparse Local Patch Transformer for Robust Face Alignment and Landmarks Inherent Relation Learning》
code: Jiahao-UTS/SLPT-master (github.com)
出发点
landmark之间的内在联系对于人脸对齐的性能有很大影响,本文重点考虑其内在联系。
之前的方法有heatmap regression,Coordinate regression,有着不同方面的劣势。
创新点
提出了SLPT(sparse local patch transformer)来学习query-query和representation-query关系(自适应内在关系);为了进一步提高SLPT的性能,提出了一种从粗到精的框架,使局部补丁进化为金字塔形补丁。
做法
本文的SLPT并非同DETR从完整的feature map中预测坐标,而是首先从局部patch中生成每个landmark的表示特征。
然后,使用一系列可学习的queries(称为landmark queries)来聚合表示。
基于Transformer的交叉注意机制,SPLT在每一层学习一个自适应邻接矩阵。最后,通过MLP独立预测每个landmark在其对应patch中的subpixel坐标。由于使用了稀疏的局部补丁,与其他ViT相比,输入token的数量显著减少。
为了进一步提高性能,引入了从粗到精的框架,以与SLPT结合。下图为所提出的从粗到精的框架利用稀疏的局部面片实现鲁棒的人脸对齐。根据前一阶段的landmarks裁剪稀疏的局部补丁,并将其输入到同一SLPT中以预测面部landmarks。此外,patch大小随着阶段的增加而缩小,以使局部特征演变成金字塔形式。
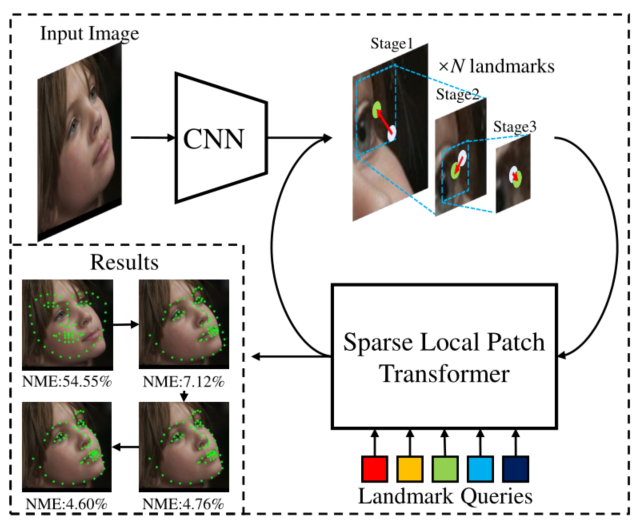
整体框架图:
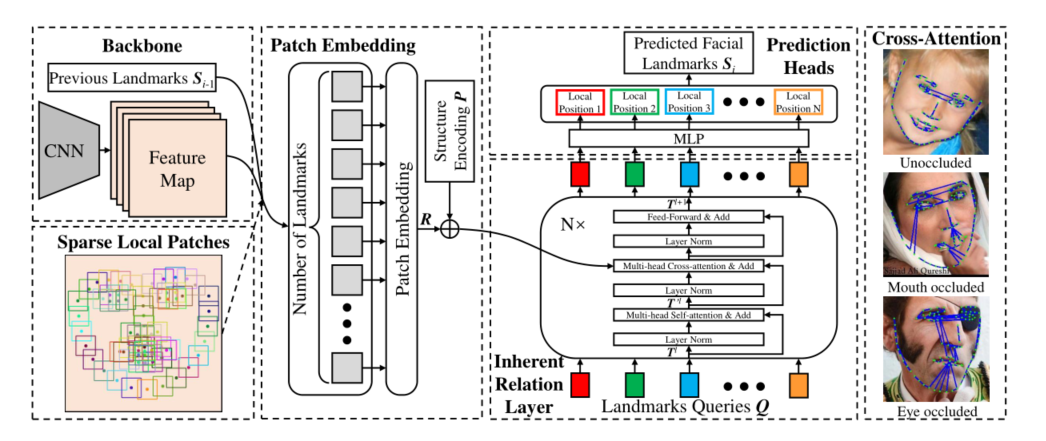
分为三部分:
the patch embedding & structure encoding
不同于ViT,SLPT先根据landmark裁剪patch,再通过线性插值将patch大小调整为K*K,又使用了结构编码(可学习的参数)来补充表示。每种编码都与相邻地标(如左眼和右眼)的编码有很高的相似性。
Muti-head Cross-attention(在Vision Transformer基础上的改进):通过landmark在CNN提取出的feature map上划取局部patch,将这些feature map上的patch排成一个patch embedding,将其视为landmark的表示;紧接着对其进行结构编码(Structure Encodeing),以获取人脸中的相对位置和patch embedding做concat。输入 landmarks queries ,通过这些MLP,独立预测每个landmark的位置。
inherent relation layers
受Transformer启发,每一层由三个块组成,即多头自注意(MSA)块、多头交叉注意(MCA)块和多层感知器(MLP)块,并且在每个块之前应用一个layer norm(LN)。
prediction heads
预测头由一个用于规范化输入的分层模板和一个用于预测结果的MLP层组成。
最右边的图像显示了不同样本的自适应固有关系。其将每个点连接到第一个内在关系层中交叉注意权重最高的点显示。